
Mobius Vision SDK (3.0.15)
Download OpenAPI specification:Download
Mobius Labs provides next-generation, state-of-the-art, industry leading Computer Vision technology for edge devices and on-premise solutions. We build technology that makes devices truly visually intelligent. With our on-premise SDK, anyone can process vast amounts of images directly on their local machines on their premises. This enables independence, data privacy, security, smooth integration and control over the data flow.
Our current suite of SDK features offers large scale image and video tagging and keywording and facial recognition and search. For images, our SDK also provides aesthetic and quality score and similarity search. And for videos, our SDK also provides automatic highlights and scene changes. With many new features currently in development, Mobius Vision SDK is on its way to become a one stop shop for all of the industries’ state-of-the-art Visual AI solutions.
What makes Mobius Vision SDK truly powerful is that it allows users to be able to personalize it for their needs. Not only Mobius Vision SDK provides pre-trained AI models out-of-the-box for myriad existing use cases, it also enables users to build their own custom AI models with incredible ease, using their own data to fit any of their niche use cases.
In the following sections, you will find how each of the different modules within the Mobius Vision SDK work. Please note that this documentation only discusses the modules and SDK features that are included in your lisence. Please contact us if you are interested in additional features offered by the Mobius SDK.
First, let us run through the software and hardware requirements and setup of the Mobius Vision SDK.
To install the Mobius On-Premise SDK, you have to follow a few steps as explained here.
We provide our solution as a combination of a python package (wheel) and a Dockerfile. Using the Dockerfile allows you to build a Docker image with everything you need to run the Mobius Vision SDK. To simplify things, we also provide a docker-compose file that takes care of building the image and running it with the correct environment variables.
The access to a zipped folder with all necessary files will be delivered to you in a shipping email.
Requirements
The hardware and software requirements for the SDK differ depending on the type of server to be used (CPU or GPU).
Hardware
For the CPU version of the SDK you need:
- Intel Haswell CPU or newer (AVX2 support necessary)
For the GPU version of the SDK you need:
- Nvidia GPU of one of the following generations: Maxwell, Pascal, Volta, Turing, Ada Lovelace (Lovelace)
AMD and Intel GPUs are not supported.
A minimum of 16GB of RAM and 50 GB Disk space. Depending on the features used and the images added to the database this may increase.
Software
In order to successfully install the Mobius Vision On-Premise SDK, the following software requirements have to be met:
- GNU/Linux x86_64 with kernel version > 3.10
- docker >= 1.12 for CPU version, 19.03 or higher for GPU version
- docker-compose >= 1.28.0 (optional, but recommended)
MacOS or Windows as a host system is not supported.
Additional Software for the GPU Version
To use a GPU, the following additional software requirements have to be met:
- docker >= 19.03
- Nvidia Drivers >= 530.41.03
- nvidia-docker2 >= 2.6.0 (for nvidia-container-toolkit)
Docker Installation
These are the installation steps to install Docker on a Ubuntu based system. Steps 2 and 3 are not strictly required, but we recommend this set-up in order to prevent running the Docker container with sudo.
If you already have Docker and docker-compose installed, you can skip these steps.
Install the Docker Container Environment (CE) https://docs.docker.com/install/linux/docker-ce/ubuntu/
Add your user to the docker group.
sudo usermod -aG docker $USER
Log out and log back in so that your group membership is re-evaluated.
Install docker-compose:
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
Verify that the installed versions are equal or newer than the requirements listed above:
docker --version
docker-compose --version
Additional Steps for GPU Version
To use the GPU version of the Mobius Vision SDK you need to have nvidia-docker2. You can install it by instructions from https://github.com/NVIDIA/nvidia-docker or our instructions below.
If you already have nvidia-docker2 installed, you can skip this step.
Add the nvidia-docker repo to apt, as explained here: https://nvidia.github.io/nvidia-docker/
Install the nvidia-docker2 package and reload the Docker daemon configuration.
sudo apt-get install nvidia-docker2
sudo service docker restart
Verify that the installed versions are equal or newer than the requirements listed above:
nvidia-smi
nvidia-docker version
Additional Steps for migration from filesystem to PostgreSQL
When delivering a new version of the SDK to you, we will tell you if this step is required.
Older versions of the SDK used a filesystem for storage purposes. New versions use PostgreSQL database. There's a way to migrate (copy) all your data from filesystem to PostgreSQL.
Start the new SDK versions with
docker-compose up
And run the migration script with
docker-compose exec mobius_sdk migrate_data
Customer Training Interface (CTI)
In case your license includes the Customer Training Interface (CTI), please unpack the corresponding zip file you got, change to that directory and import the required Docker images using the following commands:
docker image load --input cti_frontend.tar
docker image load --input cti_backend.tar
Verify that the images were imported:
docker image ls
Include the external IP of your server in the ALLOWED_ORIGINS environment variable to allow connections to the user interface from outside of the server ('CORS policy'):
export ALLOWED_ORIGINS="http://<external_ip_of_server>:8080"
You can also permanently change this variable in the docker-compose file.
Please note that the containers are only imported here and not actually started. Do not start them yourself. They are started automatically after the SDK is started using the docker-compose up command (see next section).
Running the SDK
The SDK can be started using the following commands. The first start may take a few minutes as the docker container is then automatically built using the provided Dockerfile.
unzip mobius_sdk.zip
cd mobius_sdk
docker-compose up -d
After a while, the HTTP REST API of the SDK will be usable at localhost:5000.
In case the Custom Training Interface (CTI) is included in your license, it will be started automatically afterwards and is then available at http://<ip_of_your_server>:8080. The default username is user and the default password user as well. Additional users can be created after logging in with the username admin and the password admin.
You can verify that the docker container is running with:
docker container ps
Stopping the SDK
You can stop the SDK by executing the following command in the same directory:
docker-compose down
Configuring the Setup
Optionally, the following variables can be changed in the docker-compose file before it is executed to adapt the setup to your needs:
SDK_PORT: port to access the API (default: 5000)CTI_PORT: port to access the CTI (default: 8080)NUM_WORKERS: number of workers for parallel processing, see note below (default: 20)MOBIUS_TOKEN: token to verify the validity of a particular SDK according to the license agreement (default: already set to the one included in your license)CUDA_VISIBLE_DEVICES: define which GPUs are used in case multiple GPUs are available (default: all)
NOTE: NUM_WORKERS should be carefully adjusted according to the features in the SDK (the more features are shipped in the SDK, the lower this value should be) and the available hardware (the more cores are available, the higher this value can be). We usually recommend a value between 5 and 50 for this environment variable.
The following environment variables are available for the Custom Training Interface (CTI):
ALLOWED_ORIGINS: set this to the external IP of the server to prevent misuse of the CTI backend or set it to "*" to disable this security mechanism (not recommended) (default: http://localhost:8080)POSTGRES_PASSWORDandJWT_SECRET_KEY: random strings used for additional security (default: random passwords)MAX_VIDEO_UPLOAD_SIZE: set this value to the define the maximum size of uploadable video in MB in the CTI (default: 10000)VIDEO_PREDICTION_SDK_TIMEOUT: set this to define the period in seconds which CTI should wait for a video to be processed. After this time the CTI will throw error (default is 36000).
Usage of Docker Volumes
By modifying the docker-compose file, the volumes to be used for the user data can be changed, too:
mobius_vision_data: docker volume used to store user data (metadata, indexes etc.)mobius_vision_redis: docker volume used to store redis data (database used for task status and scheduling)
You can also mount a local drive or folder to the container for faster predictions or uploads of images and videos (see the
path parameter on those endpoints). In the volumes section of the mobius_sdk service in the docker-compose file, add <path_on_host>:<path_on_container>:<flags> where
<path_on_host> is the full path to the directory to be mounted, and <path_on_container> is the point at which it will
be mounted. <path_on_container> can either be a fully qualified path, in other words beginning with /, or it can be
a relative path. If it is a relative path, it is interpreted as relative to a configurable base path which defaults to
/external. It is recommended to keep this default to ensure there are no conflicts with Linux or Docker system files.
<flags> can be any Docker volume mount flags, but ro (for read-only within the container) is strongly recommended.
For example, include /mnt/nfs/image_archive:/external/image_archive:ro in the docker-compose file, and then add a
path parameter on requests like follows: "path": "image_archive/image0001.jpg".
Checking the SDK Status
The Mobius SDK does not have a standard endpoint to check the availability of the module. However, it can be quite easily checked by passing a query image or video for prediction.
Image prediction
Simple example for calling image prediction with a query image image.jpg with default parameters.
curl "http://127.0.0.1:5000/image/predict" \
-X POST \
-F "data=@./image.jpg" \
-F params='{}'
If the SDK is running properly and the image file can be read in the preprocessing, the SDK returns a 200 response with the status success.
Video prediction
Simple example for calling video prediction with a query videovideo.mp4 with default parameters.
curl "http://127.0.0.1:5000/video/predict" \
-X POST \
-F "data=@./video.mp4" \
-F params='{}'
If the SDK is running properly and the video file can be read in the preprocessing, the SDK returns a 200 response with the status success.
Accessing logs
In case of errors, logs may help us to fix the problem faster.
You can access them by running:
docker-compose logs
Image predictions are a core functionality of the Mobius on-premise SDK. All modules for images that have been shipped with your SDK can be queried for prediction output with the predict endpoint.
Pre-trained Modules and Train Endpoints
Most modules are pre-trained and can be used out of the box; module-dependent parameters can be used to customize the modules to your use case. Some modules need to be trained first in order to be used (e.g., customized training).
Please refer to the corresponding module description section in the sidebar (or with the links in the parameter description) to learn more on how to implement workflows for the train endpoints.
Input Parameters
This endpoint comes with a range of parameters to customize the behaviour of this functionality. modules parameter is used to pass an array specifying which modules to predict with. The parameters are grouped with the relevant module and submodule. You can find detailed descriptions of the meaning of the parameters in the explanation section of each module.
The path and url parameters may be used to specify a data file(image file or downloaded pkl feature file) on the local system or a remote host, respectively, instead of including an image file in the request form data. Only one of a data file, the path parameter, and the url parameter may be specified on single request.
Parallel Processing
To get maximum performance out of the SDK run multiple requests at the same time. The difference between parallel and sequential processing could be quite dramatic. For example, it takes 17 seconds to process 1 000 images in parallel mode and 144 seconds in sequential mode (times could be different on your instance and your set of features).
Here is an example code in Python that can be used to process images in parallel.
import requests, json
import threading
from concurrent.futures import ThreadPoolExecutor
images = ['./image.jpg', './image2.jpg', './image3.jpg']
host = '127.0.0.1:5000'
params = {}
def predict_on_image(path, params, host):
with open(path, 'rb') as image:
r = requests.post(
'http://%s/image/predict'%(host),
files={'data': image},
data={'params': json.dumps(params)}
)
output = r.json()
return output
with ThreadPoolExecutor(max_workers=20) as executor:
def worker_func(path):
return predict_on_image(path, params, host)
results = list(zip(images, executor.map(worker_func, images)))
Extract Features from Image
Request Body schema: multipart/form-data
object | |
| data required | string <binary> Image file |
Responses
Request samples
- Payload
- cURL
- Python
{ "modules": [ "search/image_features" ] }
Response samples
- 400
{- "status": "error",
- "message": "data_payload_required"
}Predict on Image
Endpoint for predictions on a query image_id with module selection and a range of optional parameters.
Request Body schema: multipart/form-data
object (image_predict_params) | |
| data required | string <binary> Image file |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "modules": [ "face_recognition/cluster", "detection/object_matching", "tags/standard_concepts", "aesthetics/quality_score", "aesthetics/stock_score", "aesthetics/custom_styles", "search/identities", "search/similarity", "segmentation/rust", "segmentation/clouds", "search/text_search", "search/concept_search", "detection/custom_detection", "segmentation/custom_segmentation", "tags/custom_concepts", "detection/logo_detection" ], "tags": { "standard_concepts": { "confidence_threshold": 0.5, "top_n": 100, "categories_enabled": true }, "custom_concepts": { "custom_concept_id_list": [ "leather jacket", "spiderman" ] } }, "search": { "similarity": { "top_n": 5, "filter": [ "identities" ] }, "identities": { "top_n": 5 } }, "aesthetics": { "custom_styles": { "custom_style_id_list": [ "minimalism", "still life" ] } }, "face_recognition": { "identities": { "group_id_list": [ "default", "test" ] } }, "segmentation": { "rust": { "confidence_threshold": 0, "output_type": "base64" }, "clouds": { "confidence_threshold": 0.27, "output_type": "base64" } }, "detection": { "object_matching": { "object_id_list": [ "2ea8955a-939d-4a1c-93a6-34d68c06446c", "652f695c-0ded-4062-ba0b-be26398e28d2", "a6bd062f-45f7-4068-8299-9a39222c9753", "baf5ebe6-0962-4fd8-9c41-0c3a377ec1ec" ], "allow_missing": true }, "custom_detection": { "custom_detector_id_list": [ "car", "person" ], "allow_missing": true, "detection_mode": "multiclass", "annotation_type": "dict" }, "logo_detection": { "min_size": 24, "confidence_threshold": 0.8, "annotation_type": "dict", "group_id_list": [ "default" ] } } }, "data": "..." }
Response samples
- 200
- 400
{- "tags": {
- "standard_concepts": [
- {
- "category": "food & drink",
- "tags": [
- {
- "name": "food and drink",
- "score": 0.9984448552131653
}, - {
- "name": "healthy eating",
- "score": 0.9495988488197327
}, - {
- "name": "produce",
- "score": 0.9495988488197327
}
]
}, - {
- "category": "photographic",
- "tags": [
- {
- "name": "close-up",
- "score": 0.8976536989212036
}, - {
- "name": "full frame",
- "score": 0.6704474091529846
}
]
}
], - "custom_concepts": [
- {
- "name": "leather jacket",
- "score": 0.9984448552131653
}, - {
- "name": "spiderman",
- "score": 0.9495988488197327
}
]
}, - "aesthetics": {
- "quality_score": 0.95,
- "stock_score": 0.01,
- "custom_styles": [
- {
- "name": "leather jacket",
- "score": 0.9984448552131653
}, - {
- "name": "spiderman",
- "score": 0.9495988488197327
}
]
}, - "face_recognition": [
- {
- "identity": [
- {
- "group_id": "default",
- "person_id": "Leo Varadkar"
}
], - "emotions": [
- "happy"
], - "bounding_box": {
- "left": 152,
- "upper": 47,
- "right": 1034,
- "lower": 1196
}
}
], - "search": {
- "similarity": [
- {
- "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c",
- "distance": 0.1
}, - {
- "image_id": "652f695c-0ded-4062-ba0b-be26398e28d2",
- "distance": 0.15
}, - {
- "image_id": "a6bd062f-45f7-4068-8299-9a39222c9753",
- "distance": 0.2
}, - {
- "image_id": "baf5ebe6-0962-4fd8-9c41-0c3a377ec1ec",
- "distance": 0.25
}, - {
- "image_id": "e9d77914-e53a-4940-835d-fd45423e3223",
- "distance": 0.3
}
], - "identities": [
- {
- "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c",
- "distance": 0.1
}, - {
- "image_id": "652f695c-0ded-4062-ba0b-be26398e28d2",
- "distance": 0.15
}, - {
- "image_id": "a6bd062f-45f7-4068-8299-9a39222c9753",
- "distance": 0.2
}, - {
- "image_id": "baf5ebe6-0962-4fd8-9c41-0c3a377ec1ec",
- "distance": 0.25
}, - {
- "image_id": "e9d77914-e53a-4940-835d-fd45423e3223",
- "distance": 0.3
}
]
}, - "detection": {
- "object_matching": {
- "object_id": "Obj_A",
- "location": {
- "x": 100,
- "y": 100
}, - "positive_distance": 300,
- "negative_distance": "None"
}, - "custom_detection": [
- {
- "custom_detector_id": "bmw",
- "bounding_box": {
- "left": 142,
- "upper": 67,
- "right": 220,
- "lower": 129
}, - "score": 0.5
}, - {
- "custom_detector_id": "benz",
- "bounding_box": {
- "left": 427,
- "upper": 334,
- "right": 670,
- "lower": 370
}, - "score": 0.66
}
], - "logo_detection": [
- {
- "bounding_box": {
- "left": 152,
- "upper": 47,
- "right": 200,
- "lower": 80
}, - "logo_info": [
- {
- "group_id": "default",
- "image_id": "6273b7bd-8b06-45ca-a380-c8641b98c029",
- "logo_id": "adidas",
- "score": 0.89
}
]
}, - {
- "bounding_box": {
- "left": 301,
- "upper": 200,
- "right": 350,
- "lower": 260
}, - "logo_info": [
- {
- "group_id": "default",
- "image_id": "0095be46-4f08-4412-a533-db47eced4a29",
- "logo_id": "gucci",
- "score": 0.9
}
]
}
]
}, - "status": "success",
- "params": {
- "modules": [
- "face_recognition/cluster",
- "detection/object_matching",
- "tags/standard_concepts",
- "aesthetics/quality_score",
- "aesthetics/stock_score",
- "aesthetics/custom_styles",
- "search/identities",
- "search/similarity",
- "segmentation/rust",
- "segmentation/clouds",
- "search/text_search",
- "search/concept_search",
- "detection/custom_detection",
- "segmentation/custom_segmentation",
- "tags/custom_concepts",
- "detection/logo_detection"
], - "face_recognition": {
- "exclude_low_quality_faces": false,
- "sharpness_threshold": 3,
- "yaw_threshold": 50,
- "age_return_mode": "number",
- "identities": {
- "group_id_list": [
- "default"
]
}, - "emotions": {
- "intensity_threshold": 0,
- "distance_threshold": 0.45,
- "group_id_list": [
- "default"
]
}
}, - "aesthetics": {
- "custom_styles": { }
}, - "tags": {
- "standard_concepts": {
- "confidence_threshold": 0.55,
- "categories_enabled": true,
- "config_name": "default",
- "lang": "en"
}, - "custom_concepts": {
- "allow_missing": false
}
}, - "search": {
- "similarity": {
- "top_n": 100,
- "filter": [
- "identities"
]
}, - "identities": {
- "top_n": 100
}
}, - "segmentation": {
- "rust": {
- "output_type": "base64"
}, - "clouds": {
- "output_type": "base64",
- "confidence_threshold": 0.27
}
}, - "detection": {
- "object_matching": {
- "allow_missing": false
}, - "custom_detection": {
- "allow_missing": false,
- "detection_mode": "multilabel",
- "annotation_type": "dict"
}, - "logo_detection": {
- "min_size": 24,
- "confidence_threshold": 0.83,
- "annotation_type": "dict",
- "group_id_list": [
- "default"
]
}
}, - "image_database": {
- "store_results": false,
- "use_for_search": false,
- "update_index": false,
- "partition_id": "default"
}
}
}To predict the standard concepts, i.e. 10 000 pre-trained concepts that come with the Mobius Vision SDK, on an image, use the /image/predict endpoint and pass tags/standard_concepts as the module name in the modules list.
Confidence Scores and Thresholding
Our SDK returns a confidence score with each concept. The confidence score indicates the degree of confidence of our artificial intelligence of the term being a match to the visual content of the image. A value of 1.0 would indicate the AI is very confident that the concept is present in the image, while a score of 0.0 indicates that the model is certain the concept is not present. The results are sorted by confidence scores in descending order (highest to lowest), and outputs with a confidence score below 0.55 are removed from the results list by default.
NOTE: In the default settings, the number of results of the standard concepts module typically varies between 5 and 50 concepts per image.
The parameter confidence_threshold can be set by the user to customize the lowest confidence level below which the results are filtered out.
Top-N Selection
For some applications it might be useful to restrict the maximum number of concepts to be returned. For such use cases, the optional top_n parameter can be set to cut off the concept predictions so that only the top_n highest scored concepts are returned.
It’s also possible to get exactly N tags by combining the confidence threshold and the top_n parameter: set the confidence threshold to 0 and the top_n parameter to desired value N.
The Mobius SDK provides the ability to train any number of new concepts. This way users can define new concepts instead of using predefined set of concepts.
To predict the custom concepts use the /image/predict endpoint and add tags/custom_concepts in the modules list and specify the list of the custom concepts IDs in custom_concept_id_list under tags/custom_concepts.
A general workflow is summarized as follows:
- Add images to the image database using the endpoint /system/database/images/add
- Assign images to
positiveclass using the endpoint /image/tags/custom_concepts/assign - Assign images to
negativeclass using the endpoint /image/tags/custom_concepts/assign - Train custom concept using the endpoint /image/tags/custom_concepts/train
- Predict custom concepts using the endpoint /image/tags/custom_concepts/predict to predict concepts on the images that are already added to the image database or the general endpoint /image/predict.
Adding Images
To add images to the image database use the endpoint /system/database/images/add.
The image database is shared between different modules of the SDK so you need to add an image only once and use the same image_id for different custom concepts and even different modules.
See Image Database section to learn more about the image database.
Assigning Images
To assign images that are considered positives for particular custom concept to class positive use the endpoint /image/tags/custom_concepts/assign. We also recommend using parallel processing to add images.
Do the same for negative images. Negative images are optional but we highly recommend adding negative images to achieve better performance.
We assume that the user knows the basics of how to curate sets of image samples, and what is meant by assigning a positive or negative class to an image. If you are not sure please reach out to your delivery manager at the Mobius team as data curation guideline documentation can be provided.
Training
Once images are assigned to a custom concept use the endpoint /image/tags/custom_concepts/train to train it.
The training phase might take some time depending on the number of images that are assigned to positive and negative classes. A part of the response of the train endpoint is a unique task_id of the training task. Use the endpoint /system/tasks/status/get to check the progress of training. The status can be either in_queue, ongoing, success or error. Use this endpoint to find out when the training is completed (status is success or error) and the custom concept can be used for prediction.
Predict
There are two ways to predict custom concept:
Use the endpoint /image/tags/custom_concepts/predict to predict concepts on the images that are already added to the image database. It's the fastest way to get predictions for custom concepts because all required information is already extracted from the images. This way you can process thousands of images per second.
Use the general endpoint /image/predict to get predictions from an image.
The second option is much slower especially if you need to process the same image multiple times. We advice to add all your images to the image database of the SDK first and then use the endpoint /image/tags/custom_concepts/predict.
Custom Concept Management
The SDK offers some utility endpoints to manage custom concepts. You can perform the following actions:
- Delete a custom concept
- Get the list of all custom concept IDs
- Upload a custom concept
- Download a custom concept
NOTE: Please be aware that using
deleteis irreversible unless you have a backup of the SDK data volume or custom concept is downloaded.
Improving a Custom Concept
A custom concept is rarely trained perfectly after the first iteration. That's why we advise to do multiple iterations of the training.
- After each training run a custom concept on a set of unlabeled images. We call it a validation set. For quicker processing add validation set images to the image database.
- Label images that are misclassified and assign them to their corresponding classes.
- Train the custom concept.
- Repeat until performance is acceptable.
- Test final version of the custom concept on a new set of images: a test set. A test set is supposed to be sampled the same way as a validation set. Make sure that images in a test set do not belong to a validation set or to the images that were used for training. If performance on a test set is as desired, then you have a custom concept that is ready to be used in the production.
Face Recognition module of the Mobius Vision SDK returns the following information from an image:
- List of faces in an image.
° Bounding Box for each face to specify where it is located in the input image. The output format specifies the respective edge coordinates in the image:
{left, lower, right, upper} - Identity of the person, if it is already registered in the identity database, along with the group that the person belongs to.
- Detected gender of the person,
maleorfemale. - Estimated age of the person, in
years.
This is also illustrated in the following image.

All of this information is accessed by using the image/predict endpoint and specifying face_rec ognition under the module key in the parameters object sent with the request.
In order to train the Mobius SDK to recognize any number of faces desired, a user simply needs to add the faces to the identity database. Please see the Identity Database section to learn how that is done and managed.
Calling /image/face_recognition/identities/predict with the following payload. The face recognition in this endpoint performs faster because the prediction is done on images already added to the database.
A common usecase for this would be running face recognition on images in the database after updating the identities. This will try to identify people in the images using the updated identities.
You need to pass it the image ids where to identify people and the groups to use for identification.
image_id_list - specify a list of images where you want to identify the people
group_id_list - specify a list of groups where you added identities
Run face recognition with image IDs.
Endpoint to trigger rescan of images and detect new faces.
Request Body schema: multipart/form-data
object (batch_face_image_identity_predict_payload) |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "image_id_list": [ "2ea8955a-939d-4a1c-93a6-34d68c06446c", "06637448-9a10-4a53-80d1-ed82c281d557" ], "group_id_list": [ "default", "my_custom_search_group" ], "update_in_place": true } }
Response samples
- 200
- 400
{- "status": "success",
- "face_recognition": [
- {
- "image_id": "45457a6b-9dc6-4353-aa2c-f6866666f78e",
- "identities": [
- {
- "bounding_box": {
- "left": 432,
- "lower": 78,
- "right": 523,
- "upper": 203
}, - "emotions": [
- "happy"
], - "identity": [
- {
- "group_id": "default",
- "image_id": "45457a6b-9dc6-4353-aa2c-f6832e8af78e",
- "person_id": "Martin Compston",
- "score": 0.6559267336593386
}
]
}, - {
- "bounding_box": {
- "left": 632,
- "lower": 78,
- "right": 823,
- "upper": 803
}, - "emotions": [
- "happy"
], - "identity": [
- {
- "group_id": "default",
- "image_id": "45457a6b-9dc6-4353-aa2c-f6832e8af78e",
- "person_id": "Vicky McLure",
- "score": 0.6522555336593386
}
]
}
]
}
]
}Face clustering feature allows you to find unidentified / improperly identified faces in the image database
Adding images
Before clustering may be used, a set of images should be added to the image database.
This can be done by using endpoint /system/database/images/add.
Parameter partition_id may be specified to indicate that particular set of images belong to partition. Only faces from same partition will be clustered. If not specified, images are added to default partition. The use_for_search parameter has to be set to True.
Clustering endpoint
Clustering endpoint /image/face_recognition/cluster may be called to cluster all faces with certain partition_id. Clusters are analyzed to find an unknown faces or faces that look like 2 or more identities within certain partition_id.
As clustering is a long operation, a part of the response of the cluster endpoint is a unique task_id of the cluster task.
Use the endpoint /system/tasks/status/get to check the progress of task. The status can be either in_queue, ongoing, success or error. Use this endpoint to find out when the clustering is completed (status is success or error) and the custom detector can be used for prediction.
This endpoint is only supported in the Postgres version. Faces that were added to the filesystem version and then migrated to Postgres will be ignored.
Input Parameters
Clustering endpoint comes with a range of parameters to customize the behaviour of this functionality.
partition_id parameter is used to specify a partition of the image database (should correspond with partition_id used when adding images). If not specified, faces from default partition will be clustered.
top_n parameter specifies a number of clusters of faces returned
group_id specifies a group of identities used for face identification (should correspond with group of identity database)
min_num_faces specifies the minimum number of faces in a cluster. If the cluster has fewer faces than this, it will be discarded.
Result
Result of clustering task will be presented in /system/tasks/status/get after task is completed.
Response will include unknown_identities attribute, holding a list of unidentified / improperly identified clusters.
Each cluster has a list of faces in it, and each face has these attributes:
image_id - identifier of the image, where this face was found
bounding_box - coordinates of the face on the image
identity and distance - optional attributes, only represented when some identity was matched with the face.
Each cluster will also contain faces_found which is the number of faces inside this cluster.
Request samples
- Payload
- cURL
- Python
{ "params": { "partition_id": "c541e836-a0f8-4c1c-90cf-d4295ea5da82", "notification_url": "https://example.com/webhook" } }
Response samples
- 200
{- "status": "in_queue",
- "task_id": "a29ef5f6-3e67-42cb-badc-dca189ec372f"
}The Aesthetics module of the Mobius Vision SDK provides information about the aesthetic qualities of the input image.
The aesthetic score of an image can be accessed by using the image/predict endpoint and specifying aesthetics under the module key in the parameters object sent with the request.
The following information will be returned.
The quality score is a pre-trained module that assesses generic image quality based on its artistic merits. For most general use cases, the quality score provides the most reasonable aesthetic quality assessment.
The quality score is represented by a number between 0 and 1. The higher the score, the more aesthetically pleasing the image is.
If only the quality score is desired, then specify the aesthetics/quality_score module under the modules key in the parameters object sent with the request on the image/predict endpoint.
The stock score is a pre-trained module that can be used to evaluate how stocky an image looks to a human. We consider an image as "stocky" if it has the common look of a microstock image. For example a stocky image could be a picture of an object on a very simple white background or a clearly staged photograph of human models.
The stock score is represented by a number between 0 and 1. The lower the score, the more stocky image is.
If only the stock score is desired, then simply specify the aesthetics/stock_score module under the modules key in the parameters object sent with the request on the image/predict endpoint.
The Custom Style module enables users to train custom aesthetic assessment models to score images based on any style a user wants for its application.
An example would be Brand Compliance. A company or a brand can train the Mobius SDK to recognize its distinct style and make sure that any images representing the company or the brand on its website or externally, adhere to that unique stylistic preference.
To predict the custom styles use the /image/predict endpoint and add aesthetics/custom_styles in the modules list and specify the list of the custom style IDs in custom_style_id_list under aesthetics/custom_styles.
A general workflow for training a custom style is summarized as follows:
- Add images to the image database using the endpoint /system/database/images/add
- Assign images to
positiveclass using the endpoint /image/aesthetics/custom_styles/assign - Assign images to
negativeclass using the endpoint /image/aesthetics/custom_styles/assign - Train custom style using the endpoint /image/aesthetics/custom_styles/train
- Predict custom style using the endpoint /image/aesthetics/custom_styles/predict to predict styles on the images that are already added to the image database or the general endpoint /image/predict.
Adding Images
To add images to the image database use the endpoint /system/database/images/add.
The image database is shared between different modules of the SDK so you can add an image only once and use the same image_id for different custom styles and even different modules.
See Image Database section to learn more about the image database.
Assigning Images
To assign images that are considered positives for particular custom style to class positive, use the endpoint /image/aesthetics/custom_styles/assign. We also recommend using parallel processing to add images.
Do the same for negative images. Negative images are optional but we highly recommend adding negative images to achieve better performance.
We assume that the user knows the basics of how to curate sets of image samples, and what is meant by assigning a positive or negative class to an image. If you are not sure please see the explanation section on training or reach out to your delivery manager at the Mobius team as data curation guideline documentation can be provided.
Training
Once images are assigned to a custom style, use the endpoint /image/aesthetics/custom_styles/train to train it.
The training phase might take some time depending on the number of images that are assigned to positive and negative classes. A part of the response of the train endpoint is a unique task_id of the training task. Use the endpoint /system/tasks/status/get to check the progress of training. The status can be either in_queue, ongoing, success or error. Use this endpoint to find out when the training is completed (status is success or error) and the custom style can be used for prediction.
Predicting
There are two ways to predict custom style:
Use the endpoint /image/aesthetics/custom_styles/predict to predict styles on the images that are already added to the image database. It's the fastest way to get predictions for custom styles because all required information is already extracted from the images. This way you can process thousands of images per second.
Use the general endpoint /image/predict to get predictions from an image.
The second option is much slower especially if you need to process the same image multiple times. We advice to add all your images to the image database of the SDK first and then use the endpoint /image/tags/custom_styles/predict.
Custom Style Management
The SDK offers some utility endpoints to manage custom styles. You can perform the following actions:
- Delete a custom style
- Get the list of all custom style IDs
- Upload a custom style
- Download a custom style
NOTE: Please be aware that using
deleteis irreversible unless you have a backup of the SDK data volume or custom style is downloaded.
Improving a Custom Style
A custom style is rarely trained perfectly after the first iteration. That is why we advise to do multiple iterations of the training.
- After each training run a custom style on a set of unlabeled images. We call it a validation set. For quicker processing add validation set images to the image database.
- Label images that are misclassified and assign them to their corresponding classes.
- Train the custom style.
- Repeat until performance is acceptable.
- Test final version of the custom style on a new set of images: a test set. A test set is supposed to be sampled the same way as a validation set. Make sure that images in a test set do not belong to a validation set or to images that were used for training. If performance on a test set is as desired, then you have a custom style that is ready to be used in the production.
Assign Image IDs to a Custom Style
Endpoint to assign images as either positive or negative samples for a custom style.
Request Body schema: multipart/form-data
object (custom_style_assign_params) |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "image_id_list": [ "2ea8955a-939d-4a1c-93a6-34d68c06446c", "06637448-9a10-4a53-80d1-ed82c281d557" ], "custom_style_id": "landscape", "class": "positive" } }
Response samples
- 200
- 400
{- "status": "success"
}Get all Custom Style IDs
Endpoint to return all available custom styles.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "page": 1, "per_page": 1000 } }
Response samples
- 200
- 400
{- "status": "success",
- "custom_style_id_list": [
- "minimalism",
- "still life"
]
}Delete a Custom Style
An endpoint to delete a custom style.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "custom_style_id": "landscape" } }
Response samples
- 200
- 400
{- "status": "success"
}Download a Custom Style
Endpoint to download a custom style.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "custom_style_id": "test" } }
Response samples
- 200
- 400
<bytes (zip file)>
Predict Custom Styles by Image IDs
Endpoint to predict on images for custom styles.
Request Body schema: multipart/form-data
required | object (custom_styles_params) |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "custom_style_id_list": [ "leather jacket", "spiderman" ], "image_id_list": [ "2ea8955a-939d-4a1c-93a6-34d68c06446c", "06637448-9a10-4a53-80d1-ed82c281d557" ] } }
Response samples
- 200
- 400
{- "predictions": [
- {
- "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c",
- "aesthetics": {
- "custom_styles": [
- {
- "name": "leather jacket",
- "score": 0.9984448552131653
}, - {
- "name": "spiderman",
- "score": 0.9495988488197327
}
]
}, - "status": "success"
}, - {
- "image_id": "06637448-9a10-4a53-80d1-ed82c281d557",
- "aesthetics": {
- "custom_styles": [
- {
- "name": "leather jacket",
- "score": 0
}, - {
- "name": "spiderman",
- "score": 0.54
}
]
}, - "status": "success"
}
], - "status": "success"
}Train a Custom Style
Endpoint to train a custom style.
Request Body schema: multipart/form-data
object (custom_styles_train_params) |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "custom_style_id": "landscape", "num_clusters": 1, "apply_aesthetic_scores": [ "aesthetics/quality_score", "aesthetics/stock_score" ], "notification_url": "https://example.com/webhook" } }
Response samples
- 200
- 400
{- "status": "success",
- "task_id": "8a5c057e-85bc-44fe-8885-83cf1e0180c8"
}Upload a Custom Style
Endpoint to upload an already trained custom style.
Request Body schema: multipart/form-data
object | |
| data required | string <binary> Custom style data file |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "custom_style_id": "test" }, "data": "..." }
Response samples
- 200
- 400
{- "status": "success"
}The Search module allows you to perform different types of search. Here is the list of search options that are available to you:
- Similarity search
- Identity search
- Free-text search
A general workflow of the search is summarized as follows:
- Add images to the image database using the endpoint /system/database/images/add
- Train the search module /image/search/train
- Do similarity search using the endpoint /image/predict.
- Do identity search using the endpoint /image/predict.
- Do free-text search using the endpoint /image/search/text_search.
It might be desired to add more images to the search module after training. The workflow for that procedure is following:
- Add new images to the image database using the endpoint /system/database/images/add. This procedure by itself doesn’t add images to the search module because indexes need to be updated as well.
- Update the search module using the train endpoint /image/search/train. This procedure will add newly added images to the existing indexes. If you want to retrain indexes from scratch use parameter
retrain. - Do similarity search using the endpoint /image/predict.
- Do identity search using the endpoint /image/predict.
- Do free-text search using the endpoint /image/search/text_search.
To add images to the image database use the endpoint /system/database/images/add.
The image database is shared between different modules of the SDK so you can add an image only once and use the same image_id for different modules that use the image database.
For image to be considered as part of the search module, you need to set use_for_search param to True. By setting update_index to True, the image will be added immediately into the search module, otherwise you need to update the search module.
See Image Database chapter to learn more about the image database.
Once images are added to the image database use the endpoint /image/search/train to train search module.
The training phase might take some time. A part of the response of the train endpoint is a unique task_id of the training task. Use the endpoint /system/tasks/status/get to check the progress of training. The status can be either in_queue, ongoing, success or error. Use this endpoint to find out when the training is completed (status is success or error) and the similarity search can be used.
The parameter retrain can be used to force the search module to retrain indexes from scratch. By default, its value is set to false.
To update the indexes without starting from scratch, you can add or remove images dynamically. Simply set the update_index parameter to true when adding or removing images from the image database.
Use the endpoint /image/predict to perform the search. You can specify which type of search you want to perform in the modules key of the parameters. See descriptions below for more information of specific types of search that are available to you.
There are a few settings for the search module.
The endpoint /image/search/settings/get can be used to get the current state of the search module settings.
The endpoint /image/search/settings/set can be used to set the state of the search module settings.
image_prob can be used to manage trade-offs between speed and accuracy of the similarity search. The value is between 0 and 1. Lower values means faster search and higher values means more accurate predictions. We recommend to use value 0.1 but you can always adjust it using the endpoint /image/search/settings/set.
identity_prob can be used to manage trade-offs between speed and accuracy of the identity search. The value is between 0 and 1. Lower values means faster search and higher values means more accurate predictions. We recommend to use value 0.1 but you can always adjust it using the endpoint /image/search/settings/set.
text_prob can be used to manage trade-offs between speed and accuracy of the free-text search. The value is between 0 and 1. Lower values means faster search and higher values means more accurate predictions. We recommend to use value 0.1 but you can always adjust it using the endpoint /image/search/settings/set.
text_prob can be used to manage trade-offs between speed and accuracy of the custom concept text search. The value is between 0 and 1. Lower values means faster search and higher values means more accurate predictions. We recommend to use value 0.1 but you can always adjust it using the endpoint /image/search/settings/set.
The similarity search module of the Mobius Vision SDK allows users to find visually similar images to an input image.
Similarity search results are obtained using the endpoint /image/predict by passing in the search/similarity parameter under the modules key.
The parameter top_n can be used to control the number of results that will be returned. The default value is set to 100, meaning only the top 100 closest matches will be returned.
Additional filters can be added to the search by specifying the parameter filters. The list of available filters for similarity search:
- Identities filter can be used to search for similar images with the same people as in the query image.
The identity search module allows to search for the images with the same people as in the query image. It can be useful if you need to find all the images where a particular person appears. You don’t even need to know the name of the person, one good photo of the face is sufficient.
Identity search results are obtained using the endpoint /image/predict by passing in the search/identity parameter under the modules key.
The parameter top_n can be used to control the number of results that will be returned. The default value is set to 100, meaning only the top 100 closest matches will be returned.
The free-text search module allows to search for images using text queries.
Text search results are obtained using the endpoint /image/search/text_search.
The parameter top_n can be used to control the number of results that will be returned. The default value is set to 100, meaning only the top 100 closest matches will be returned.
The custom concept search module allows to search for images using the name of any available custom concept as input. By using this feature we can quickly find the best matching images in the database for a trained custom concept.
Concept search results are obtained using the endpoint /image/search/concept_search.
The parameter top_n can be used to control the number of results that will be returned. The default value is set to 100, meaning only the top 100 closest matches will be returned for each custom concept name.
A major upgrade to the SDK may change how the search data in the database is represented, in which case a reset of the relevant database is necessary. Typically this is handled automatically, but in some cases it may be needed to do so manually. Your Mobius representative will tell you when you need to do this, as well as what additional steps - if any - need to be undertaken.
Resetting an index is also useful if you wish to erase the database and start again. Deleting each item from the database with the associated delete endpoint and then call that database's reset_default endpoint and all traces of the old data will be removed.
Remove from identities database Reset identities database index
Remove from facial expressions database Reset facial expressions database index
Perform Image Search for Custom Concepts
Endpoint for search top matching images in search database using the a custom concept id as input
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "query": "wedding", "top_n": 100 } }
Response samples
- 200
- 400
{- "status": "success",
- "results": [
- {
- "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c",
- "score": 0.95
}, - {
- "image_id": "652f695c-0ded-4062-ba0b-be26398e28d2",
- "score": 0.85
}, - {
- "image_id": "a6bd062f-45f7-4068-8299-9a39222c9753",
- "score": 0.8
}, - {
- "image_id": "baf5ebe6-0962-4fd8-9c41-0c3a377ec1ec",
- "score": 0.43
}, - {
- "image_id": "e9d77914-e53a-4940-835d-fd45423e3223",
- "score": 0.2
}
]
}Group Similar Images
Endpoint to group similar images
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "image_id_list": [ "..." ], "notification_url": "https://example.com/webhook" } }
Response samples
- 200
- 400
{- "status": "success",
- "task_id": "8a5c057e-85bc-44fe-8885-83cf1e0180c8"
}Reset Search Indexes
Resets indexes for the search module to their default state.
Request Body schema: multipart/form-data
| params | object |
Responses
Request samples
- cURL
- Python
curl "http://127.0.0.1:5000/image/search/indexes/reset_default" \ -X POST
Response samples
- 200
- 400
{- "status": "success"
}Get Search Settings
Endpoint to get settings for similarity search.
Request Body schema: multipart/form-data
| params | object |
Responses
Request samples
- cURL
- Python
curl "http://127.0.0.1:5000/image/search/settings/get" -X POST
Response samples
- 200
- 400
{- "status": "success",
- "identity_prob": 0.1,
- "image_prob": 0.1,
- "text_prob": 0.1,
- "output_distance": true
}Set Search Settings
Endpoint to set settings for the search module.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "identity_prob": 0.1, "image_prob": 0.1, "text_prob": 0.1, "output_distance": true } }
Response samples
- 200
- 400
{- "status": "success"
}Search similar images database.
Endpoint for predictions on a query image with module selection and a range of optional parameters.
Request Body schema: multipart/form-data
object (image_search_from_features) |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "modules": [ "search/similarity" ], "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c", "search": { "similarity": { "top_n": 5, "filter": [ "identities" ] } } } }
Response samples
- 200
- 400
{- "search": {
- "similarity": [
- {
- "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c",
- "distance": 0.1
}, - {
- "image_id": "652f695c-0ded-4062-ba0b-be26398e28d2",
- "distance": 0.15
}, - {
- "image_id": "a6bd062f-45f7-4068-8299-9a39222c9753",
- "distance": 0.2
}, - {
- "image_id": "baf5ebe6-0962-4fd8-9c41-0c3a377ec1ec",
- "distance": 0.25
}, - {
- "image_id": "e9d77914-e53a-4940-835d-fd45423e3223",
- "distance": 0.3
}
]
}, - "status": "success"
}Request samples
- Payload
- cURL
- Python
{ "params": { "query": "cat", "top_n": 100 } }
Response samples
- 200
- 400
{- "status": "success",
- "results": [
- {
- "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c",
- "distance": 0.1
}, - {
- "image_id": "652f695c-0ded-4062-ba0b-be26398e28d2",
- "distance": 0.15
}, - {
- "image_id": "a6bd062f-45f7-4068-8299-9a39222c9753",
- "distance": 0.2
}, - {
- "image_id": "baf5ebe6-0962-4fd8-9c41-0c3a377ec1ec",
- "distance": 0.25
}, - {
- "image_id": "e9d77914-e53a-4940-835d-fd45423e3223",
- "distance": 0.3
}
]
}Train Image Search
Endpoint to train image similarity search approximator with images that have been added to the image database.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "retrain": false, "notification_url": "https://example.com/webhook" } }
Response samples
- 200
- 400
{- "status": "success",
- "task_id": "8a5c057e-85bc-44fe-8885-83cf1e0180c8"
}The Mobius SDK provides the ability to train custom detection models with no code procedure.
Overview
Each object detection concept will be defined by two components, a base model and a custom detector. A base model acts like a feature extractor for the custom detector. Custom detectors related to the close concepts can use the same base model and can act like a model cluster to predict and also train together. For object detection concepts which are working on different fields, it's better to use different base models. Mobius Labs will provide at least one pre-trained base model with the SDK that corresponds to the customer’s use case, possibly multiple base models if the customer needs distinct enough clusters of concepts that training multiple base models is worthwhile; Otherwise it is possible to create different base models using pre-trained base model provided as default by the SDK and customize those base models by deep training.
To predict with the custom detector use the /image/predict endpoint and add detection/custom_detection in the modules list and specify the list of the custom detector IDs in custom_detector_id_list under detection/custom_detection.
A general workflow is summarized as follows:
- Add images to the custom detection database using the endpoint /system/database/detection/add
- Assign bounding boxes for training to the custom detectors using the endpoint /image/detection/custom_detection/images/assign
- Create a base model if needed using endpoint /image/detection/custom_detection/models/bases/add or use an existing model.
- Train custom detectors using the endpoint /image/detection/custom_detection/models/train
- Predict custom detectors using the endpoint /image/predict.
Adding Images
To add images to the custom detection database use the endpoint /system/database/detection/add.
See Custom Detection Database section to learn more about the custom detection database.
Assigning Images
To assign the bounding boxes to the custom detector use the endpoint /image/detection/custom_detection/assign.
The bounding boxes can be provided in a variety of annotation formats. The annotation format is specified in the parameter annotation_type.
If you want to add the image that doesn't contain an object of interest, provide an empty list in the parameter boxes. Also you can specify a unlabeled set either when creating a base model or start training the model, to be used as negative samples. By default no unlabeled set will be used. See Unlabeled Imagery section to learn more about how to manage unlabeled sets.
Model Management
The SDK provides some functionalities to organize and manage custom detectors. The user can create a new base model initiated from available base models by specifying base_model_source and unlabeled_set_id using the endpoint /image/detection/custom_detection/models/bases/add. If the user does not specify the base_model_source in the request, the new base model will be initiated using the default pre-trained base model provided by the SDK.
A default unlabeled_set is provided by the SDK but the user can add his own unlabeled sets too using unlabeled_imagery endpoints. By default no unlabeled set will be used.
The detection model's accuracy is connected to its input size. Images which are fed to the model will first scale down to a specific size which causes the resolution of its objects to decrease. For detecting small objects in high resolution images, the model needs to use a larger input size, so after scaling down the image, the objects will be still recognizable by the detector. The SDK provides the option to set input size of the model by providing the input_size as a parameter when creating a new base model. The input_size should be a multiple of 32 and its minimum and maximum values are 320 and 1280 respectively. If the input_size was not provided in the request, a preset value will be set for the base model which is 480. If the user needs larger input size than 1280, the max limit can be changed via setting the DETECTION_MAX_INPUT_SIZE in the environment vars.
Also the SDK provides training and processing of large images block by block. For enabling this option, the block processing settings should be set for the base model via the /image/detection/custom_detection/models/bases/settings/set endpoint. Block processing settings contain train_size, min_size, max_size, block_size and block_overlap values. if train_size is set, the image will be resized to [train_size, train_size] first. Then any images whose height and width are smaller than the min_size will be padded to the model required size. Images with size between min_size and max_size will be warped to require size and images which are larger than mix_size will be splitted to multiple blocks with respect to block_size and block_overlap values. The relations between block processing settings are:
min_size<=block_size<=max_size- 0 <
block_overlap<block_sizeYou can benefit from a rescaling if you choose ablock_sizelarger or smaller thaninput_size, as each block of image would be resized to theinput_size.
The user can organize the base models by rename, upload, download or delete them.
Custom detectors can be trained by the user from scratch by training new ones using a base model and some data or uploaded to the SDK. Multiple custom detectors can be trained together if their concepts are close together. In that case the images should be labeled with all the concepts for best performance. Like base models, custom detectors can be organized by rename, upload, download or delete them. Also the settings for each custom detector can be changed by using the endpoint /image/detection/custom_detection/models/concepts/settings/set with new settings.
The SDK does not support creating multiple base or concept models with the same names and the user should provide the unique ID for each of them and handle the ID to Name mapping himself.
User can get status of custom detection module by using the endpoint /image/detection/custom_detection/models/status/get which provides the information below:
- List of all available unlabeled sets
- List of all base models with their configs (trained status, owner, ...)
- List of all custom detectors with their configs (base_model_id, settings, ...)
- List of available custom detectors that can be used for prediction
- List of default custom detectors used for prediction
Training
Once at least a base model is added and bounding boxes are assigned to a custom detector, use the endpoint /image/detection/custom_detection/models/train to train it. It is also possible to use another unlabeled set rather than the one listed on the base model by specifying unlabeled_set_id in the training request.
If you want to train multiple concepts at once, ensure all the concepts' objects are assigned in each of the training images.
The training phase will take a few minutes. A part of the response of the train endpoint is a unique task_id of the training task. Use the endpoint /system/tasks/status/get to check the progress of training. The status can be either in_queue, ongoing, success or error. Use this endpoint to find out when the training is completed (status is success or error) and the custom detector can be used for prediction.
Custom detection allows training multiple detectors at the same time. The detector IDs can be provided as a list in the parameter custom_detector_id_list and the base model which those detectors should use.
Also custom detection supports different modes for training such as full, shared_and_tail and tail. full and shared_and_tail training is beneficial if a lot of data is available and the detector is very specific. To select each mode set training_mode to desire one. The disadvantage of the full and shared_tail is that previously trained detectors which use that base model are not compatible with the model trained with shared_and_tail and full mode and WILL BE REMOVED.
If your objects of interest are very small regard to the training images' resolution and there is any limitation for increasing the base model's input_size, it is possible to use block processing in training phase. For this purpose create a base model with largest possible input_size and then train the model with desire synthetic input size by setting train_size and block size option in the /image/detection/custom_detection/models/train endpoint. The block_size should be bigger than objects' resolutions for better accuracy. By default the block_size is equal to the base model input_size. After the training is done, the optimal block processing settings will be set automatically for prediction, but it is possible to change them via the /image/detection/custom_detection/models/bases/settings/set endpoint if needed.
Resetting the Unlabeled Imagery Database
If you have made changes to the default unlabeled imagery database(s) that came with your SDK, you can reset them with the /system/unlabeled_imagery/reset_default endpoint. This may also be necessary if you have upgraded your SDK with a new version of custom object detection; in this case your Mobius representative will inform you and what additional steps, if any, need to be performed.
Predict
To predict with the custom detector use the /image/predict endpoint and add detection/custom_detection in the modules list and specify the list of the custom detector IDs in custom_detector_id_list under detection/custom_detection.
You can also specify the annotation format for the output using annotation_type parameter under detection/custom_detection.
It is possible to declare a list of custom detectors as default for prediction using the endpoint /image/detection/custom_detection/models/default/set, so then the user can avoid specifying custom_detector_id_list in the requests.
The Mobius SDK has the ability to detect and recognize +1000 different logos inside of images.
To activate the logo detection, pass detection/logo_detection as the module name in the modules list of /image/predict endpoint.
Logo Management
The SDK provides some functionalities to organize and manage logo templates used for logo recognition. It is possible to create separate logo databases for detection. Each database has a unique group_id which can be used to utilize that database for prediction by mentioning the group_id inside of the request. The Mobius Labs provides a general logo database with +1000 common logos with group_id of default inside of the SDK, but users can also upload their own database or edit the default database by adding new logos to it or removing existing logos from it.
You can get available logo database ids by using the /system/database/logos/group_ids/get endpoint. Each group_id corresponds to an existing logo database. For listing available logos inside of each database you can use the /system/database/logos/logo_ids/get endpoint with its group_id. If the number of logos inside of a group is very large it is recommended to retrieve a paginated response by specifying the page and per_page values inside of the request. Each logo database consists of some positive templates for each logo and many negative templates which are used for pruning incorrectly detected logos. Each template has a unique image_id. For listing templates of a specific logo inside of a group use /system/database/logos/image_ids/get endpoint. The user can add a new template for a logo by providing an image of that logo by using /system/database/logos/add endpoint. The logo template then would be extracted automatically by SDK and stored inside of the requested logo group. The reference of that image also can be stored inside of the SDK for later management if save_reference has been set inside of the request. You can then retrieve the logo template reference by using /system/database/logos/reference_image/get endpoint to check which logo template is related to which image.
To add an image which contains no logos as a negative template, use /system/database/logos/add endpoint with logo_id of NEGATIVE_LOGO.
To remove a specific logo template from a logo specify its template image_id and logo's group_id using /system/database/logos/delete_image endpoint. For removing entire templates of a logo at once, use /system/database/logos/delete_logo endpoint.
Also to install a new logo group from tar file or take a backup from a logo group use upload or download endpoints respectively.
If you have made changes to the logo database included with your SDK and wish to undo those changes and restore the defauls, you can use the /system/database/logos/reset_default endpoint for the logo database. This may also be necessary if you have upgraded your SDK and a new version of the logo detection model is available; in most cases this is handled automatically and your Mobius representative will inform you if you need to take any action and what further steps are required.
See Logo Database section to learn more about the logo detection database.
Logo Detection Params
The SDK provides a list of parameters for manipulate the output of the logo detection module as listed below:
- confidence_threshold
- group_id_list
- min_size
- annotation_type
confidence_threshold will filter the matched logo templates based on the matching score of each logo templates existed on the SDK. Matching score indicates how well a logo template is matched to a detected logo inside of the input image. A value of 1.0 would indicate the detected logo is as similar as one of existing logo templates, while a score of 0.0 indicates that no template inside of the database is similar to the detected image. By using the confidence_threshold you can filter the low matched detected logos.
By specifying a list of group_id inside of group_id_list you can choose which logo database should utilize for logo detection. If not specified, the default database would be used for template matching.
min_size value specifies the minimum dimension of detected logos inside of the input image. If a detected logo is too small, recognizing it would be error prone. The default value of this param is 24 pixel which means detected logos smaller than 24 * 24 pixels will be removed from the logo detection output.
You can also specify the annotation format for the output using the annotation_type parameter. Supported annotation types are albumentations, pascal_voc, coco, yolo, mobius and dict.
For using any of the above parameters, specify it under detection/logo_detection in /image/predict endpoint.
Assign Image ID to a Custom Detector
Endpoint to assign images and box boundaries for object detection.
Request Body schema: multipart/form-data
object (custom_detection_assign_params) |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c", "annotation_list": [ { "custom_detector_id": "face", "boxes": [ { "left": 10, "right": 200, "upper": 50, "lower": 250 } ] } ] } }
Response samples
- 200
- 400
{- "status": "success"
}Unassign Image ID from a Custom Concept
Endpoint to unassign images for object detection.
Request Body schema: multipart/form-data
object (custom_concepts_unassign_params) |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c", "custom_detector_id": "face" } }
Response samples
- 200
- 400
{- "status": "success"
}Get Base Model Config
Endpoint to get base model's config
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "base_model_id": "test" } }
Response samples
- 200
- 400
{- "status": "success",
- "config": {
- "base_model_id": "cloud_base",
- "model_architecture": "resnet50",
- "status": "untrained",
- "unlabeled_set_id": "set_1",
- "input_size": [
- 512,
- 512
], - "settings": {
- "min_size": 256,
- "max_size": 512,
- "block_size": 512,
- "block_overlap": 256
}
}
}Download a Base Model
Endpoint to download a base model.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "base_model_id": "logo_base" } }
Response samples
- 200
- 400
<bytes (zip file)>
Rename a Base Model
Endpoint to rename a base model.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "from": "logo_base", "to": "cloud_base" } }
Response samples
- 200
- 400
{- "status": "success"
}Set Base Model Block Size Settings
Endpoint to set base model block processing settings
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "base_model_id": "test", "settings": { "train_size": 1280, "min_size": 256, "max_size": 512, "block_size": 512, "block_overlap": 256 } } }
Response samples
- 200
- 400
{- "status": "success"
}Upload a Base Model
Endpoint to upload a base model.
Request Body schema: multipart/form-data
object | |
| data required | string <binary> Base model data file Note: tarfile should contain |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "base_model_id": "test" }, "data": "..." }
Response samples
- 200
- 400
{- "status": "success"
}Get Custom Detector's Config
Endpoint to get custom detector's config
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "custom_detector_id": "bmw_logo" } }
Response samples
- 200
- 400
{- "status": "success",
- "config": {
- "custom_detector_id": "concept_1",
- "base_model_id": "logo_base",
- "base_model_ref": "sdk",
- "settings": {
- "confidence_threshold": 0.5,
- "nms_threshold": 0.4
}
}
}Delete a Custom Detector
Endpoint to delete custom detector.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "custom_detector_id": "face" } }
Response samples
- 200
- 400
{- "status": "success"
}Download a Custom Detector Model
Endpoint to download a custom detector model.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "custom_detector_id": "helmet" } }
Response samples
- 200
- 400
<bytes (zip file)>
Rename a Custom Detector
Endpoint to rename a custom detector.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "from": "helmet", "to": "casquette" } }
Response samples
- 200
- 400
{- "status": "success"
}Get Custom Detections' Settings
Endpoint to get custom detectors' settings
Request Body schema: multipart/form-data
| params | object |
Responses
Request samples
- cURL
- Python
curl "http://127.0.0.1:5000/image/detection/custom_detection/models/concepts/settings/get" -X POST
Response samples
- 200
- 400
{- "status": "success",
- "settings": [
- {
- "custom_detector_id": "concept_1",
- "settings": {
- "confidence_threshold": 0.5,
- "nms_threshold": 0.4
}
}, - {
- "custom_detector_id": "concept_2",
- "settings": {
- "confidence_threshold": 0.5,
- "nms_threshold": 0.44
}
}
]
}Set Custom Detector's Settings
Endpoint to set custom detector settings
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "custom_detector_id": "test", "settings": { "confidence_threshold": 0.55, "nms_threshold": 0.4 } } }
Response samples
- 200
- 400
{- "status": "success"
}Unassign Custom Detector's all Images
Endpoint to delete custom detector.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "custom_detector_id": "face" } }
Response samples
- 200
- 400
{- "status": "success"
}Upload a Custom Detector Model
Endpoint to upload a custom detector model.
Request Body schema: multipart/form-data
object | |
| data required | string <binary> Custom detector model data file Note: tarfile should contain |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "custom_detector_id": "test" }, "data": "..." }
Response samples
- 200
- 400
{- "status": "success"
}Set Default Custom Detectors
Endpoint to set default custom detectors for prediction
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "custom_detector_id_list": [ "face" ] }
Response samples
- 200
- 400
{- "status": "success"
}Get Custom Detections' Status
Endpoint to get custom detectors' settings
Request Body schema: multipart/form-data
| params | object |
Responses
Request samples
- cURL
- Python
curl "http://127.0.0.1:5000/image/detection/custom_detection/models/status/get" -X POST
Response samples
- 200
- 400
{- "status": "success",
- "base_model_list": [
- {
- "base_model_id": "logo_base",
- "model_architecture": "mobilenet",
- "status": "trained",
- "unlabeled_set_id": "default",
- "input_size": [
- 480,
- 480
], - "settings": "None"
}, - {
- "base_model_id": "cloud_base",
- "model_architecture": "resnet50",
- "status": "untrained",
- "unlabeled_set_id": "set_1",
- "input_size": [
- 512,
- 512
], - "settings": {
- "min_size": 256,
- "max_size": 512,
- "block_size": 512,
- "block_overlap": 256
}
}
], - "custom_detector_list": [
- {
- "custom_detector_id": "concept_1",
- "base_model_id": "logo_base",
- "base_model_ref": "sdk",
- "settings": {
- "confidence_threshold": 0.5,
- "nms_threshold": 0.4
}
}, - {
- "custom_detector_id": "concept_2",
- "base_model_id": "logo_base",
- "base_model_ref": "usr",
- "settings": {
- "confidence_threshold": 0.5,
- "nms_threshold": 0.44
}
}, - {
- "custom_detector_id": "concept_3",
- "base_model_id": "car_base",
- "base_model_ref": "usr",
- "settings": {
- "confidence_threshold": 0.5,
- "nms_threshold": 0.44
}
}
], - "available": [
- "concept_1",
- "concept_2"
], - "default": [
- "concept_2"
], - "active": [
- "concept_2"
]
}Train a Custom Detector
Endpoint to train a custom detectors.
Request Body schema: multipart/form-data
object (custom_detection_train_params) |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "base_model_id": "face_base", "custom_detector_id_list": [ "face" ], "training_mode": "tail", "notification_url": "https://example.com/webhook" } }
Response samples
- 200
- 400
{- "status": "success",
- "task_id": "8a5c057e-85bc-44fe-8885-83cf1e0180c8"
}The Mobius Vision SDK provides the ability to perform transcription, translation and audio tagging on the spoken content of the audio/video files.
One important thing to note when processing audio with the Mobius SDK is that since video/audio files are typically large, it takes some time for the SDK to process the whole video/audio. Therefore, the /audio/predict call only returns a task_id and not predictions immediately. Use the endpoint /system/tasks/status/get to check the audio processing progress. The status can be in_queue, ongoing, success or error. If the status is success then the status response will also contain the results of video/audio processing. If the status is error check the field message to get the name of the error.
Audio notes
Ffmpeg is used internally in the SDK which supports most popular audio/video codecs like AAC, H.264, H.265, OPUS, VP8, VP9 and several file formats like MP3, MOV, MPEG, MXF, MP4, FLV, MKV.
Currently the SDK can only work on one track/channel at a time. If a multitrack/multichannel audio is sent to the SDK they are mixed into a single channel before being processed.
Audio processing supports a number of modules. The supported modules are transcribe, translate, lang_id and audio_tags. You can specify one or more modules. If not specified, the SDK performs run all available modules on the audio/video.
Language Identification Module
The lang_id module performs language identification on the audio/video. The language identification is the process of determining the language of the audio/video. It is also known as language detection.
The language identification is not available for the multilingual audio/video at the moment.
If you already know the language of the audio/video, you can specify it using the input_language parameter and remove the lang_id module from the modules parameter. Forcing the language is useful to speed up the processing and also when the language identification model is not able to identify the language correctly.
Transcription Module
The transcribe module performs transcription on the audio/video.
Transcription is the process of converting the spoken content of the audio/video into text. It is also known as speech-to-text. You can specify the language of the audio/video using the input_language parameter. If not specified, the SDK will automatically identify the language of the audio/video.
transcribe module supports following languages with their language codes:
- English: 'en'
- Catalan: 'ca'
- Czech: 'cs'
- Danish: 'da'
- German: 'de'
- Greek: 'el'
- Spanish: 'es'
- Finnish: 'fi'
- French: 'fr'
- Indonesian: 'id'
- Italian: 'it'
- Japanese: 'ja'
- Dutch: 'nl'v
- Polish: 'pl'
- Portuguese: 'pt'
- Romanian: 'ro'
- Swedish: 'sv'
- Tamil: 'ta'
- Thai: 'th'
- Turkish: 'tr'
- Croatian: 'hr'
- Hungarian: 'hu'
- Slovak: 'sk'
- Arabic: 'ar'
- Chinese: 'zh'
- Tagalog: 'tl'
- Galician: 'gl'
- Hindi: 'hi'
- Korean: 'ko'
- Malay: 'ms'
- Norwegian: 'no'
- Russian: 'ru'
- Ukrainian: 'uk'
- Vietnamese: 'vi'
The transcription is available at audio_level and segment_level. The audio_level transcription contains the full text of the audio/video. The segment_level transcription contains the transcription for each segment of the audio/video. Each segment also contains the word-level predictions. The word-level predictions are available only if the word_level_enabled parameter is set to True. The word-level predictions contain the word-level timestamps for each word in the segment.
If your audio/video contains multiple languages, this will be automatically transcribed in code-switched format for transcribe module. The audio/video will be automatically translated to english if the module is set to translate. The multilingual parameter is set to True by default which enables this. This parameter can be set to False to get improved inference speed for monolingual audio/video.
Translation Module
The translate module performs translation on the audio/video from a language of the source to English.
Translation is the process of converting the spoken content of the audio/video from one language to another. It is also known as machine translation. Right now, the SDK supports translation only to English from the set of supported languages.
translate module supports following languages. Keep in mind that the translation is always from the language of the audio/video to English.
- Bulgarian
- Bosnian
- Catalan
- Czech
- Danish
- German
- Spanish
- Tagalog
- French
- Galician
- Croatian
- Indonesian
- Italian
- Korean
- Macedonian
- Malayalam
- Malay
- Norwegian
- Dutch
- Polish
- Portuguese
- Romanian
- Russian
- Slovak
- Serbian
- Swedish
- Turkish
- Ukrainian
The translation is available at audio_level and segment_level. The audio_level translation contains the full text of the audio/video. The segment_level translation contains the translation for each segment of the audio/video. Each segment also contains the word-level predictions. The word-level predictions are available only if the word_level_enabled parameter is set to True. The word-level predictions contain the word-level timestamps for each word in the segment.
If your audio/video contains multiple languages, you need to set the multilingual parameter to True. The multilingual processing is also known as code-switched processing. The multilingual parameter is set to False by default.
Audio Tags Module
The audio_tags module performs tagging on the audio/video.
Tags are the words or phrases that describe the content of the audio/video. The tags are also known as keywords.
If the audio_tags module is requested, the transcribe or translate module will be enabled based on the detected language or input_language, if available. The tags are extracted from the transcription or translation of the audio/video.
Tags module only works for English. If the audio/video is not in English, translate module is enabled to translate the audio/video to English. If the audio/video is in English, then the transcribe module is used to extract the tags.
The SDK provides a number of parameters to control the audio processing.
The main parameter is modules which specifies the modules to be performed on the audio/video. Supported modules are transcribe, translate, lang_id and audio_tags. You can specify one or more modules. If not specified, the SDK performs transcribe task for the audio/video.
Transcription and Translation Parameters
The transcribe and translate modules have the following parameters:
input_language: This optional parameter specifies the language of the audio/video.If you know the language of the audio/video, you can specify it here to skip language identification. Forcing the language is useful when the language identification model is not able to identify the language correctly.
If not specified, the intelligent language identification model in the SDK will automatically identify the language as one of the 99 supported languages.
The
input_languageparameter takes ISO 639-1 language code (a double character language code) as input. For example,enfor English,esfor Spanish,frfor French, etc.multilingual: Specifies whether the audio/video should be processed as multilingual. IfTrue, the audio/video is processed as code-switched audio/video. IfFalse, the audio/video is processed as monolingual. Defaults toTrue. Hence thetranscribemodule generates a hybrid (code-switched) formatted output whereas atranslatemodule generates anen(english language) output text. For a faster inference on monolingual videos, this parameter can be set toFalse.word_level_enabled: Optional parameter (defaultTrue) to extract word-level timestamps and include the timestamps for each word in each segment. Using word-level timestamps also improves the accuracy of the segment-level timestamps.vad_filter: Optional parameter (defaultTrue) to enable voice activity detection (VAD) to filter out parts of the audio without speech.prompt: This optional parameter specifies a string to consider as an initial prompt to the model. Prompts can be very helpful for correcting specific words or acronyms that the model often misrecognizes in the audio, such as domain-specific words such as DALL·E, which was previously written as "DALI". This can also be used to define the style of the transcription output by specifying an example. Note that the effect of this might not be prevalent beyond a certain duration of the audio and can slightly affect the consistency. Use prompts if they are necessary. Below are some useful scenarios:
Tags Parameters
The audio_tags module has the following parameters:
custom_keywords: Optional parameter to specify the list of custom keywords to be displayed. The custom keywords can be one ofBrand/logo Names,Person Names, andProfanity. If not specified, the SDK displays all the custom keywords.enable_tf_idf: Optional parameter (defaultFalse) to enable TF-IDF to get relevant tags.tf_idf_relevancy: Optional parameter (defaultgeneral) to determine the document type to be selected to get the relevant verbs. One ofgeneralandmovies. This parameter is used only ifenable_tf_idfis enabled.
The lang_id module has the following parameters:
vad_filter: Optional parameter (defaultTrue) to enable voice activity detection (VAD) to filter out parts of the audio without speech.language_detection_segments: The number of highly confident audio segments to decide the language of the video/audio (default is4). Only used forlang_idmodule.
The SDK returns audio transcription, translation and tags at different levels of granularity: audio-level, segment-level, and word-level within each segment.
The SDK also returns the identified language of the audio/video and the confidence of the language identification.
Language Identification
The language identification consists of the identified language of the audio/video and the confidence of the language identification.
language denotes the identified language of the audio/video and language_confidence denotes the confidence of the language identification. The confidence is a value between 0.0 and 1.0. Higher the value, the model is more confident that the identified language is correct. Note that when multilingual is set to True (default), the detected language will be one of the major languages in the multilingual video (all languages will be detected in our future version of SDK).
Audio-level Predictions
The audio-level predictions consist of the transcription, translation and tags for the audio/video.
The transcription contains the full text of the audio/video. Note that the audio is considered as multilingual by default.
The translation contains the translated text of the audio/video. The translation is available only if the translate module is requested. The translation is always from the language of the audio/video to English.
The tags contain the list of tags identified in the audio/video. The tags are available only if the audio_tags module is requested.
The tags have the following format:
name: Name of the tag.count: The number of times the tag appears in the audio/video.timestamps: A list of starting times (in seconds) of all occurrences of the tag.pos_tag: Part of speech tag of the tag. It can benoun,verb,entityornoun group.label: Specific label or subtype of thepos_tag(default isNone). The label can also be based on audio processing optional input parameters. Below are the possible values forlabel.entitysubtype can be one ofPERSON,ORG,EVENT,DATE,CARDINAL,ORDINAL,NORP,None,TIME,GPE.verbsubtype can optionally have TF-IDF relevancy ofmoviesorgeneralvideos.- It can also be one of the
analyse_taskskeywords as the label. One ofPerson Names,Brand/logo Names, andProfanity.
Here is an example of the audio-level predictions:
{
'transcription': " Ich glaube, wir müssen vor allem eingestehen...",
'translation': " I think we have to admit that we have to deal with a huge secret...",
'tags': [
{
'name': 'think',
'timestamps': [1.5],
'pos_tag': 'verb',
'label': None,
'count': 1
},
{
'name': 'admit',
'timestamps': [2.8],
'pos_tag': 'verb',
'label': None,
'count': 1
},
...
]
}
Segment-level Predictions
The segment-level predictions, just like the audio-level predictions, consist of the transcription, translation and tags for each segment of the audio/video.
The segments for transcription, translation and tags might be different and that's why they are separated into different lists.
The segments for transcription and translation have the following format:
timestamp: The dictionary containing the start and end times of the segment.start: Start time of the segment in seconds.end: End time of the segment in seconds.
text: The transcription/translation of the segment.confidence: The confidence of the model on the output segment. Higher the value, the model is more confident that the output is correct.no_speech_confidence: The confidence of the model that the segment does not contain any speech.words: Word-level alignments. The word-level can be enabled/disabled using theword_level_enabledparameter. It is enabled by default because it improves the accuracy of the segment-level timestamps. The word-level alignments have the following format:raw_word: The word in the segment.word: The processed word (removed punctuation marks and spaces).alignment_confidence: The confidence of the model on the word position.timestamp: The dictionary containing the start and end times of the word.start: Start time of the word in seconds.end: End time of the word in seconds.
The segments for tags have the following format:
timestamp: The dictionary containing the start and end times of the segment.start: Start time of the segment in seconds.end: End time of the segment in seconds.
tags: The list of audio tags in the segment. The tags have the same format as the audio-level tags.
Here is an example of segment-level predictions:
{
'transcription': [
{
'timestamp': {'start': 1.06, 'end': 3.0},
'text': ' Ich glaube, wir müssen vor allem eingestehen,',
'confidence': 0.9227307727717466,
'no_speech_confidence': 0.3559136688709259,
'words': [
{
'raw_word': 'Ich',
'word': 'Ich',
'timestamp': {'start': 1.06, 'end': 1.52},
'alignment_confidence': 0.4463876187801361},
{
'raw_word': 'glaube',
'word': 'glaube',
'timestamp': {'start': 1.52, 'end': 1.82},
'alignment_confidence': 0.988440990447998
},
...
]
},
...
],
'translation': [
{
'timestamp': {'start': 0.9, 'end': 6.24},
'text': ' I think we have to admit that we have to deal with a huge secret.',
'confidence': 0.7699799895513403,
'no_speech_confidence': 0.3559136688709259,
'words': [
{
'raw_word': 'I',
'word': 'I',
'timestamp': {'start': 0.9, 'end': 1.5},
'alignment_confidence': 0.46306395530700684
},
{
'raw_word': 'think',
'word': 'think',
'timestamp': {'start': 1.5, 'end': 1.86},
'alignment_confidence': 0.6788601279258728
},
...
]
},
...
],
'tags': [
{
'timestamp': {'start': 0.9, 'end': 6.24},
'tags': [
{
'name': 'think',
'timestamps': [1.5],
'pos_tag': 'verb',
'label': None,
'count': 1
},
{
'name': 'admit',
'timestamps': [2.8],
'pos_tag': 'verb',
'label': None,
'count': 1
},
...
]
},
...
]
}
Audio Processing
Request Body schema: multipart/form-data
object | |
| data required | string <binary> A video/audio file to perform audio tagging. |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "input_language": "de", "module": [ "transcribe" ], "modules": [ "transcribe", "lang_id", "translate", "audio_tags" ] }, "data": "..." }
Response samples
- 200
- 400
{- "status": "success",
- "task_id": "8a5c057e-85bc-44fe-8885-83cf1e0180c8"
}The Mobius Vision SDK provides various AI modules that can extract a variety of information from an input video.
The Mobius Vision SDK is shipped with a number of modules for video processing. All modules for video that have been shipped with your SDK can be queried for prediction output with the /video/predict endpoint.
One important thing to note when processing videos with the Mobius SDK is that since videos are typically large files, it takes some time for the SDK to process the whole video. Therefore, the /video/predict call only returns a task_id and not predictions immediately. Use the endpoint /system/tasks/status/get to check the progress of video processing or use a webhook to be notified when the analysis is finished using the notification_url parameter and then get the results using this endpoint. The task status can be either in_queue, ongoing, success or error. If the status is success then the status response will also contain the results of video processing. If the status is error check the field message to get the name of the error.
A video can be seen as a sequence of images, which are called frames. Video content is typically recorded at 24 to 60 frames per second (fps). The Mobius Vision SDK processes videos on a frame by frame basis. By default, we do not use the original frame rate of the video as the processing time grows linearly with the number of frames that are processed, and content typically does not change too rapidly. Usually we use 3 frames per second for predictions, which can be changed if needed. In the rare case that frame-accurate results are required, you can use the value -1 for the extraction_fps parameter to analyze every single frame of the video.
There are a few important terms that a user needs to understand in order to be able to fully utilize the Mobius SDK's video processing. When a user calls the /video/predict endpoint, the SDK returns predictions at four levels: segment, subsegment, frame-level and video-level. These are described in the following in more detail.
Segment-level: A Segment is a collection of frames where the scene-content does not change substantially. The SDK uses an intelligent shot detector which partitions the video into a set of semantically meaningful segments. Each segment contains predictions along with the corresponding confidence scores. A segment is sometimes also referred to as 'shot' and the start and end times of the segments can be seen as shot-boundaries.
Subsegment level: To allow for more accurate localization concepts (in time), the SDK further splits video segments into fixed-length subsegments. At the default frame extraction rate of 3 fps, the subsegments are around 2.5 seconds long. Each subsegment contains predictions along with the corresponding confidence scores. This can be used to get more fine-granular prediction results in a certain shot. If the extraction_fps is set to -1 and the subsegment_length to 1, there will be exactly one subsegment per original frame of the video.
Frame level: To allow for tracking identities in the video, the SDK returns each identity and its face bounding box in each extracted frame of video (3 fps by default). Frame level prediction is not available in fast mode and the face recognition module should be available for video prediction to detect the faces for frame_level output. Frame level just contains frames which at least one identity detected on it, so each item in frame_level has a timestamp to indicate when it is started and when is ended.
Video-level: Video-level predictions consist of all predictions that appear in at least one segment of the video. For each video-level prediction, the SDK returns two values: a confidence score and a value that reflects how long the prediction appears in the video, referred to as duration . As such, the video-level predictions along with their confidence scores and durations can be seen as a way of summarizing the video.
If the face recognition module is enabled for video prediction, each of the four levels contain the identities of the recognized faces in the face_recognition field. A preview thumbnail of a recognized identity can be accessed by using the endpoint /system/database/identities/reference_image/get if it is already in the face identity database, or endpoint video/thumbnails/unknown_identity/download if it was tagged as an unknown person (recognized by person_id similar to [Unknown X]).
There are a few general video processing parameters that are applied to every module:
extraction_fpsspecifies the number of frames per second (FPS) extracted from the video for processing. Default value is3. Higher rate will take longer for processing, but will analyse finer transitions in the video giving more information. If set to-1, every single original frame will be analyzed. This is very resource intensive and can result in large prediction outputs, so only use this if really necessary.pooling_window_lengthdefines the number of frames over which smoothing of the predictions will be applied.video_level_enabledis the flag that enables the output of video-level predictions. Default value istrue.segment_level_enabledis the flag that enables the output of segment-level predictions. Default value istrue.subsegment_level_enabledis the flag that enables the output of subsegment-level predictions. Default value istrue.frame_level_enabledis the flag that enables the output of frame-level predictions. Default value isfalse.thumbnails_enabledis the flag that enables the saving of previews for segment and subsegment. The previews can be accessed later by using the endpoint /video/thumbnails/subsegment/download and endpoint /video/thumbnails/segment/download. Default value isfalse.unknown_face_enabledis the flag that enables the saving of previews for unknown identities faces if the face is not found in any listed identities groups in the request. The previews can be accessed later by using the endpoint video/thumbnails/unknown_identity/download. Default value isfalse.subsegment_lengthdefines the length of each subsegment as the number of frames in regards to theextraction_fpsframerate. If theextraction_fpsis set to 10 and the subsegment_length is 20, then each subsegment is 2 seconds long (20 frames / 10 fps = 2s). This length should be shorter than the expected length of a shot, but still larger than 1 to allow the 'pooling' / smoothing of prediction results over multiple extracted frames.pathandurlparameters may be used to specify a file on the local system or a remote host, respectively. Only one of adatafile, thepathparameter, and theurlparameter may be specified on single request.notification_urlis the HTTP POST endpoint to notify when processing the video is finished. For authorization and encryption of the request, you can set these environment variables when running the SDK:NOTIF_AUTH=Bearer NOTIF_TOKEN=myToken NOTIF_SECRET=StrongSecretIf
NOTIF_SECRETis not set, the data will not be encrypted.
The payload of the notification is a JSON object with a status field and the task_id of the video analysis task. This task_id can then be used to retrieve the full analysis output from the SDK using the /system/tasks/status/get endpoint. After the results and face thumbnails were retrieved, they can also be deleted from the SDK using the /video/results/delete endpoint to free up the storage.
The payload also contains a repetition of the metadata of the analyzed video (also found in the analysis output) that can for example be used for usage tracking by keeping track of the video lengths.
The webhook should return a success response (e.g. status code 200) to the SDK.
Here is an example code in Python that can be used to implement the webhook handler with flask.
from flask import Flask, jsonify, request
import jwt
app = Flask(__name__)
secret = 'StrongSecret'
@app.route('/webhook', methods=['POST'])
def webhook():
headers = request.headers
auth_info = headers.get('Authorization')
# Authorization with token
# ...
payload = request.get_json()['data']
if secret:
payload = jwt.decode(payload, secret, algorithms=["HS256"])
task_id = payload.get('task_id')
task_status = payload.get('status')
return jsonify({
'status': 'success',
})
if __name__ == "__main__":
app.run(host='0.0.0.0', port='5000')
Delete Video's visualDNA Features from DB
Remove video features ("visualDNA") from the SDKs internal database. Should be called if you have saved the visualDNA features by setting store_features to True and no longer need it for more predictions.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "video_id": "8a5c057e-85bc-44fe-8885-83cf1e0180c8" } }
Response samples
- 200
- 400
{- "status": "success"
}Download Video Features (visualDNA file)
Download a "visualDNA" file for a video. This file can later be used with /video/features/predict to get updated predictions for the video without the actual video file.
Can only be used after extracting features or doing predictions on a video file (or frames) where the store_features parameter was set to true.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "video_id": "2d70b861-89d6-4e5f-8c6d-8b24c18c1298", "delete_after_download": true } }
Response samples
- 400
- 404
{- "status": "error",
- "message": "error_message"
}Extract visualDNA Features from Video
Only extracts the visualDNA features from a video but does not return the actual predictions yet. The visualDNA data can then be used in a second step with /video/features/predict to get the actual predictions without the video file. For retrieving the visualDNA data you can use /video/features/download endpoint to download it as a tar file. If you have set 'store_features' to True when extracting the features, you can use the task_id directly to predict on the stored visualDNa data. The feature extraction is the longest part of the analysis, the prediction is much faster.
Request Body schema: multipart/form-data
object (video_features_extract_params) | |
| data required | string <binary> Video file |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "extraction_fps": 3, "notification_url": "https://example.com/webhook", "face_recognition": { "identities": { "group_id_list": [ "default", "test" ] } } }, "data": "..." }
Response samples
- 200
- 400
{- "status": "success",
- "task_id": "8a5c057e-85bc-44fe-8885-83cf1e0180c8"
}Get Predictions using visualDNA Features
Get the actual predictions for a video using its visualDNA data (and not the actual video file). You can either use visualDNA features stored in the internal database of the SDK by providing the ID of the video, or provide an externally stored visualDNA .tar file.
With this endpoint, you can get updated predictions e.g. after adding identities to the database or training a new custom concept very fast. Please note that the parameters for /video/predict and /video/features/predict are not the same.
Request Body schema: multipart/form-data
Predict Using Features File (object) or Predict Using Stored Features (object) | |
| data | string <binary> Video features file |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "modules": [ "tags/standard_concepts", "tags/custom_concepts", "face_recognition", "highlights", "shot_detection" ], "pooling_window_length": 1, "subsegment_length": 8, "video_level_enabled": true, "segment_level_enabled": true, "subsegment_level_enabled": true, "frame_level_enabled": true, "notification_url": "https://example.com/webhook", "store_features": true, "tags": { "standard_concepts": { "confidence_threshold": 0.5, "top_n": 10, "categories_enabled": true }, "custom_concepts": { "custom_concept_id_list": [ "leather jacket", "spiderman" ] } }, "face_recognition": { "identities": { "group_id_list": [ "default", "test" ] } } }, "data": "..." }
Response samples
- 200
- 400
{- "status": "success",
- "task_id": "8a5c057e-85bc-44fe-8885-83cf1e0180c8"
}Extract visualDNA Features from Frames
Extracts the visualDNA features from already extracted video frames (but does not return the actual predictions yet). The visualDNA data can then be used in a second step with /video/features/predict to get the actual predictions without the video file.
The feature extraction is the longest part of the analysis, the prediction is much faster.
This endpoint can be useful if another part of your pipeline already extracts frames from a video. Extracting frames is time-intensive and using the already extracted frames can be faster and more efficient.
Request Body schema: multipart/form-data
object (video_frames_features_extract_params) | |
required | object <binary> Video frames tar file |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "metadata": { "fps": 3, "num_frames": 100, "fast_mode_enabled": false, "video_info": { "duration": 33.333, "width": 1920, "height": 1080, "size": 100 } }, "notification_url": "https://example.com/webhook", "face_recognition": { "identities": { "group_id_list": [ "default", "test" ] } } }, "data": "..." }
Response samples
- 200
- 400
{- "status": "success",
- "task_id": "8a5c057e-85bc-44fe-8885-83cf1e0180c8"
}Get Predictions for a Video
The most common endpoint for video predictions. It combines feature extraction and producing the actual predictions in one step.
Always use this endpoint if you want to get actual predictions for a new video. It still allows you to store the features (visualDNA) for later use with the /video/features/predict endpoint. Also use this endpoint and not the separate ones if you need segment thumbnails.
Request Body schema: multipart/form-data
object (video_all_predict_params) | |
| data required | string <binary> Video file |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "modules": [ "tags/standard_concepts", "aesthetics/quality_score", "face_recognition/identities", "highlights/general_highlights", "face_recognition/emotions", "face_recognition/face_qa", "tags/custom_concepts" ], "pooling_window_length": 1, "extraction_fps": 3, "subsegment_length": 8, "video_level_enabled": true, "segment_level_enabled": true, "subsegment_level_enabled": true, "frame_level_enabled": true, "notification_url": "https://example.com/webhook", "store_features": true, "tags": { "standard_concepts": { "confidence_threshold": 0.5, "top_n": 10, "categories_enabled": true }, "custom_concepts": { "custom_concept_id_list": [ "leather jacket", "spiderman" ] } }, "face_recognition": { "identities": { "group_id_list": [ "default", "test" ] } } }, "data": "..." }
Response samples
- 200
- 400
{- "status": "success",
- "task_id": "8a5c057e-85bc-44fe-8885-83cf1e0180c8"
}Delete Video Prediction Result and Thumbnails
Remove video prediction result (not the "visualDNA" features, just the actual prediction) and the segment and face thumbnails from the disk if they were stored. After calling this endpoint, the result of the prediction task is no longer accessible using /system/tasks/status/get. To also remove the visualDNA features, use /video/features/delete. To delete the generated visualDNA file (that is generated for downloading, in addition to storing it in the internal database), download the file using /video/features/download and set delete_after_download to true while doing so.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "task_id": "8a5c057e-85bc-44fe-8885-83cf1e0180c8" } }
Response samples
- 200
- 400
{- "status": "success"
}Download the Thumbnail for a Segment
Only works together with /video/predict and if thumbnails_enabled was set to true there. Thumbnail extraction is only available when using the combined endpoint /video/predict and not when only extracting the features of a video.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "task_id": "dc3bf3fe-3296-4022-8e50-4b4f0d40bb2f", "segment_id": 0 } }
Response samples
- 400
- 404
{- "status": "error",
- "message": "task_id_not_found"
}Download the Thumbnail for a Subsegment
Only works together with /video/predict and if thumbnails_enabled was set to true there. Thumbnail extraction is only available when using the combined endpoint /video/predict and not when only extracting the features of a video.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "task_id": "dc3bf3fe-3296-4022-8e50-4b4f0d40bb2f", "subsegment_id": 0 } }
Response samples
- 400
- 404
{- "status": "error",
- "message": "task_id_not_found"
}Download Face Thumbnail of an Unknown Identity
Get a thumbnail image of the face image for an unknown identity which was detected in a video. The unknown_face_enabled parameter has to be set to true during video analysis.
If face_recognition -> identities -> identities_database -> store_identities and face_recognition -> identities -> identities_database -> save_ref in the video prediction parameters were enabled, you can also use the /system/database/identities/reference_image/get endpoint to get the reference image of an automatically added unknown identity using its full identifier.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "task_id": "dc3bf3fe-3296-4022-8e50-4b4f0d40bb2f", "person_id": "[Unknown 11]" } }
Response samples
- 400
- 404
{- "status": "error",
- "message": "task_id_not_found"
}To predict the standard concepts, i.e. 10 000 pre-trained concepts that come with the Mobius Vision SDK, on a video, use the general /video/predict endpoint and pass tags/standard_concepts as the module name in the modules list.
Confidence Scores and Thresholding
Our SDK returns a confidence score with each keyword. The confidence score indicates the degree of confidence of our artificial intelligence of the term being a match to the visual content. A value of 1.0 would indicate the AI is very confident that the concept is present in the image, while a score of 0.0 indicates that the model is certain the concept is not present. The results are sorted by confidence scores in descending order (highest to lowest), and outputs with a confidence score below 0.55 are removed from the results list by default.
The parameter confidence_threshold can be set by the user to customize the lowest confidence level below which the results are filtered out.
Top-N Selection
For some applications it might be useful to restrict the maximum number of tags to be returned. For such use cases, the optional top_n parameter can be set to cut off the concept predictions so that only the top_n highest scored tags are returned.
It’s also possible to get exactly N tags by combining the confidence threshold and the top_n parameter: set the confidence threshold to 0 and the top_n parameter to desired value N.
Configuration File
The on-premise SDK comes with a default configuration file, named default. The user can fully customize these settings and create their own custom configuration files.
The name of the configuration file is passed during prediction time in the prediction call in order to specify which setting to use (see /tags/standard_concepts/config_name in the parameters of the /video/predict endpoint).
The naming of the configuration files enables the usage of multiple configuration files in the same SDK.
There are three endpoints to manage configuration files for the standard concepts on video:
To get more information about the configuration file refer to chapter Configuration Files for Standard Concepts.
The Mobius SDK provides the ability to train any number of new concepts. This way users can define new concepts instead of using predefined sets of concepts.
For the information on how to train custom concepts refer to the chapter Custom Concepts.
To retrieve the custom concepts, use the /video/predict endpoint add tags/custom_concepts as the module name in the modules list and add custom concept IDs to the custom_concept_id_list under tags/custom_concepts.
Following diagram gives a meaningful illustration of the results returned by the Custom Concepts module.

Mobius Vision SDK can recognize 11,000 celebrities out-of-the-box. To identify faces on videos, use the /video/predict endpoint and pass face_recognition as the module name in the modules list.
In addition, the Mobius SDK also allows users to add any number of new faces to customize the SDK for their use case. Please see the Identity Database section for information on how to add new faces.
To recognize cartoon characters in videos, do not add them to the identity database as it is only trained for human faces. Rather use custom concepts here.
Here is an overview of how the results are returned on videos.

It is possible to add newly detected unknown identities inside the video to the identity database. For this purpose set store_identities inside the face_recognition/identities section of /video/predict endpoint and set the identities group_id which you like to add new found identities into. Newly added identities info will be returned inside the info section of the video result. The user can tune below params to select which identities should be added.
min_quality: Minimum quality of face for adding it into the identities group (default: 0.8)min_frames: Minimum visited times of the unknown face inside the video (default: 15, equivalent of 3 seconds). In case of increasing the fps of video processing or using thefast_modethis params should be increased or decreased. The default processing fps of video is 3.
Using low values for min_quality and min_frames causes more low quality faces to be added into the identities database. To avoid this, min_quality should be around 0.7 or higher.
This feature allows to obtain highlight scores for video segments, which can be used to identify the most important parts of a video. This can be very useful for example in order to create a summary of a video that can be shown if someone is browsing through a video database, or to identify the highlights in a recording of unedited video.
For illustration purposes we show an example of a video that can benefit from highlighting. Someone is standing on the side of a motocross race, waiting for the race to start.
Our highlight detector is able to identify the point where the race actually starts, as identified by the spike of the highlight scores towards the end of the clip.
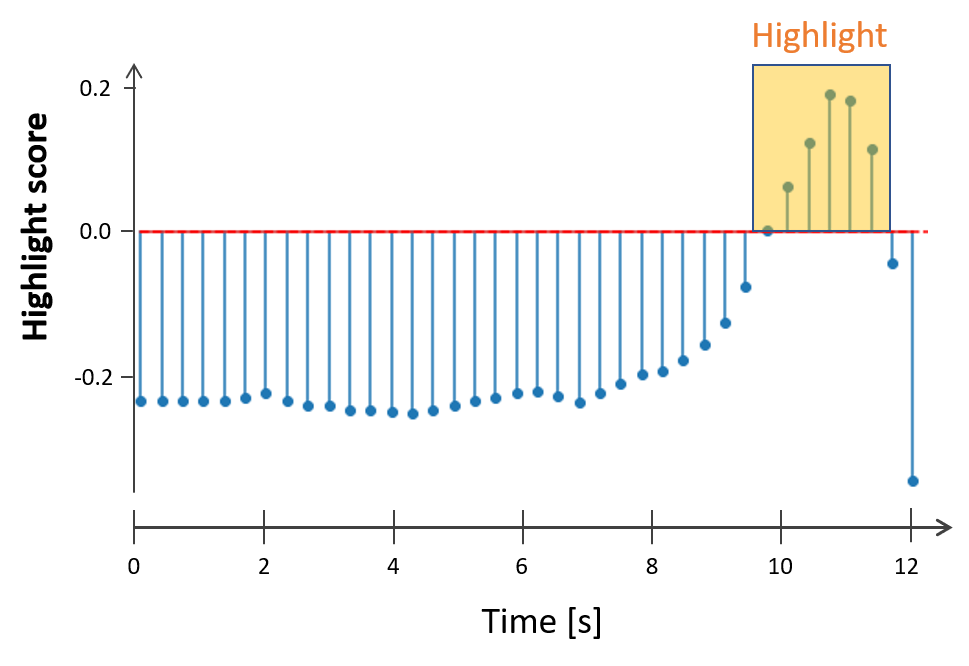
Below is the section of the video that corresponds to the identified highlight. Note that depending on the length and type of video, there can be numerous (or none) highlights detected by our highlights detector.

To extract hightlights from videos, use the /video/predict endpoint and pass highlights or highlights/general_highlights as the module name in the modules list.
This section contains endpoints that are not features by itself, but which are very useful or even necessary for the operation of the on-premise SDK.
Request samples
- cURL
- Python
curl "http://127.0.0.1:5000/system/sdk/build_info/get" -X POST
Response samples
- 200
- 400
{- "status": "success",
- "build_info": {
- "version": "3.0.4",
- "commit_hash": "ce830db7568fb72f6cdecde6d1ebe308d09726f8,",
- "models": [
- "video_keywording_clip_v2",
- "video_text_search_image_features_v2_feature_extractor",
- "text_search_image_features_v2",
- "shotbound_detector_clip_v2",
- "video_face_recognition_small_detector_v1_face_model_v3",
- "video_face_recognition_face_search",
- "face_detector_small_v1",
- "face_model_v3",
- "face_search"
], - "build_type": "cpu"
}
}Request samples
- cURL
- Python
curl "http://127.0.0.1:5000/system/models/status/get" \ -X POST
Response samples
- 200
- 400
{- "status": "success",
- "models": [
- {
- "name": "tags/standard_concepts",
- "status": "ok",
- "model_backend": "keywording_on_premise_v2.2"
}, - {
- "name": "video,",
- "model_backend": {
- "custom_concepts": "video_clip_custom_concepts,",
- "face_recognition": "video_face_recognition_small_detector_v1_face_model_v3,",
- "keywording": "video_keywording_clip_v2,",
- "keywording_features": "video_text_search_image_features_v2_feature_extractor,",
- "shot_detection": "shotbound_detector_clip_v2"
}, - "status": {
- "models": {
- "custom_concepts": "loaded,",
- "face_recognition": "loaded,",
- "keywording": "loaded,",
- "keywording_features": "loaded,",
- "shot_detection": "loaded"
}, - "video_worker": "available"
}
}
]
}Add an Image to the Image Database
Endpoint to add an image to the image database. The image database is used for the modules "image similarity","custom concept" and "custom style".
Request Body schema: multipart/form-data
object | |
| data required | string <binary> Image file |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c" }, "data": "..." }
Response samples
- 200
- 400
{- "status": "success",
- "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c"
}Count images added to the database.
Endpoint to get image count from db.
Request Body schema: multipart/form-data
| params | object |
Responses
Request samples
- cURL
- Python
curl "http://127.0.0.1:5000/system/database/images/count" \ -X POST \ -F params='{}'
Response samples
- 200
- 400
{- "status": "success",
- "count": 42
}Delete an Image from the Image Database
Endpoint to delete a specified image from the image database.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c" } }
Response samples
- 200
- 400
{- "status": "success",
- "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c"
}Check if Image ID Exists in the Image Database
Endpoint to check whether the image database has an entry for a specified image ID.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "image_id": "1ac435ec058e9985183397da76eadea3" } }
Response samples
- 200
- 400
{- "status": "success"
}Get a Random Set of Image IDs from the Image Database.
Endpoint to get a random set of image ids from the image database. If the requested amount is larger than the dataset, all the available ids will be returned, the response will also include a warning.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "num_ids": 23 } }
Response samples
- 200
- 400
{- "status": "success"
}List partitions stored in image database
Endpoint to list partitions stored in image database along with image count of each
Request Body schema: multipart/form-data
| params | object |
Responses
Request samples
- cURL
- Python
curl "http://127.0.0.1:5000/system/database/partitions/list" \ -X POST \ -F params='{}'
Response samples
- 200
- 400
[- {
- "partition_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c",
- "image_count": 100
}, - {
- "partition_id": "c541e836-a0f8-4c1c-90cf-d4295ea5da82",
- "image_count": 80000
}
]Add an Image to the Face Database
Use this endpoint to add a new image to the face database by specifying the group_id of the group the image needs to be added to.
Request Body schema: multipart/form-data
Request takes in group_id, person_id and image_id as arguments.
object | |
| data required | string <binary> Image file |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c", "person_id": "Leo Varadkar", "group_id": "test" }, "data": "..." }
Response samples
- 200
- 400
{- "status": "success",
- "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c",
- "person_id": "Leo Varadkar",
- "group_id": "test"
}Delete a Group from the Face Database
Delete an entire group from the face database.
CAUTION: Be very careful before using this endpoint. This will delete all the persons and images within the specified group from the face database!
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "group_id": "test" } }
Response samples
- 200
- 400
{- "status": "success",
- "group_id": "test"
}Delete an Image from the Face Database
Delete an image from the face database.
Note: This only deletes the image, not the person, from the database. If you want to delete a person, please use the delete_person endpoint.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c", "group_id": "test" } }
Response samples
- 200
- 400
{- "status": "success",
- "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c"
}Delete a Person from the Face Database
Delete a person from the face database by specifying the person_id and the group_id.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "person_id": "Leo Varadkar", "group_id": "test" } }
Response samples
- 200
- 400
{- "status": "success",
- "person_id": "Leo Varadkar"
}Download a Group from the Face Database
Download an entire group dataset of images and persons within a group from the face database as a .tar file.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "group_id": "test" } }
Response samples
- 200
- 400
<bytes (zip file)>
Get Group IDs from the Face Database
Get the Group IDs of all the groups in the face database.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "page": 1, "per_page": 1000 } }
Response samples
- 200
- 400
{- "status": "success",
- "group_id_list": [
- "default",
- "test",
- "mobius_core"
]
}Get Image IDs from the Face Database
Get the Image IDs of all the images within a specified group in the face database.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "page": 1, "per_page": 1000, "group_id": "default" } }
Response samples
- 200
- 400
{- "status": "success",
- "image_id_list": [
- "b687ed5d-f09d-45e0-8e82-5089b957893c",
- "4c378112-38b6-4a19-a600-873f0d9ccbf1",
- "d6c21897-6f8a-40f6-8a2a-fab1cd762277",
- "3e59de55-35c7-49c4-b661-d64f376aa6dc",
- "8a5c057e-85bc-44fe-8885-83cf1e0180c8",
- "fd02e442-e371-49a9-88b8-7511f8817710",
- "5a26d07e-bff1-449d-b142-f0231c6c27c1",
- "bb593098-8fb5-4219-88cd-063179a1d8f9",
- "69ede55c-1d42-45d0-a848-e9f2e121261f",
- "07f4c753-706a-4279-a08a-af03fd1de46a"
]
}Get Person IDs from the Face Database
Get the Person IDs of all the people within a specified group in the face database.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "page": 1, "per_page": 1000, "group_id": "default" } }
Response samples
- 200
- 400
{- "status": "success",
- "person_id_list": [
- "Audrey Hepburn",
- "John Wayne",
- "Kaley Cuoco",
- "Katie Couric",
- "Ronald Reagan"
]
}Get the Reference Image for a Face
Get the reference face image for a Person ID from the Face Database
Request Body schema: multipart/form-data
object |
Responses
Request samples
- cURL
- Python
curl "http://127.0.0.1:5000/system/database/identities/reference_image/get" \ -X POST \ -F params='{ "person_id": "Leo Varadkar", "group_id": "test" }'
Response samples
- 200
- 400
- 404
<bytes>
Upload a Group to the Face Database
Upload an entire group dataset of images and persons within a group to the face database as a .tar file.
Request Body schema: multipart/form-data
object | |
| data required | string <binary> .tar file of the group. This argument is required. |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "group_id": "test" }, "data": "..." }
Response samples
- 200
- 400
{- "status": "success"
}Reset Default Identity Database
Reset default identity database to the SDK default one.
Request Body schema: multipart/form-data
| params | object |
Responses
Request samples
- cURL
- Python
curl "http://127.0.0.1:5000/system/database/identities/reset_default -X POST
Response samples
- 200
- 400
{- "status": "success"
}Delete an Unlabeled Imagery Set
Delete an entire set from unlabeled imagery sets.
NOTE: The 'default' unlabeled imagery set is protected by sdk and can not be deleted.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "unlabeled_set_id": "test" } }
Response samples
- 200
- 400
{- "status": "success",
- "unlabeled_set_id": "test"
}Download an Unlabeled Imagery Set
Download entire images of an unlabeled imagery set as a .tar file.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "unlabeled_set_id": "default" } }
Response samples
- 200
- 400
<bytes (zip file)>
Get all Unlabeled Imagery Set IDs
Endpoint to return all available unlabeled imagery sets.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "page": 1, "per_page": 1000 } }
Response samples
- 200
- 400
{- "status": "success",
- "unlabeled_set_id_list": [
- "default",
- "custom_set"
]
}Upload an Unlabeled Imagery Set
Upload entire images of an unlabeled imagery set as a .tar file.
Request Body schema: multipart/form-data
object | |
| data required | string <binary> .tar file of the image set. This argument is required. |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "unlabeled_set_id": "test_ds" }, "data": "..." }
Response samples
- 200
- 400
{- "status": "success"
}Reset Default Imagery Database
Reset default unlabeled imagery database to the SDK default one.
Request Body schema: multipart/form-data
| params | object |
Responses
Request samples
- cURL
- Python
curl "http://127.0.0.1:5000/system/unlabeled_imagery/reset_default -X POST
Response samples
- 200
- 400
{- "status": "success"
}Add an Image to the Custom Detection Database
Request Body schema: multipart/form-data
object | |
| data required | string <binary> Image file |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c" }, "data": "..." }
Response samples
- 200
- 400
{- "status": "success",
- "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c"
}Delete an Image from the Custom Detection Database
Endpoint to delete a specified image from the custom detection database.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c" } }
Response samples
- 200
- 400
{- "status": "success",
- "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c"
}Add an Image to the Logo Database
Use this endpoint to add a new image to the logo database by specifying the group_id of the group the image needs to be added to.
Request Body schema: multipart/form-data
Request takes in group_id, logo_id, image_id and bounding_box as arguments.
object | |
| data required | string <binary> Image file |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c", "logo_id": "adidas", "group_id": "test", "bounding_box": { "left": 65, "right": 180, "upper": 220, "bottom": 260 }, "save_reference": true }, "data": "..." }
Response samples
- 200
- 400
{- "status": "success",
- "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c",
- "logo_id": "adidas",
- "group_id": "test"
}Delete a Group from the Logo Database
Delete an entire group from the logo database.
CAUTION: Be very careful before using this endpoint. This will delete all the logos and images within the specified group from the logo database!
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "group_id": "test" } }
Response samples
- 200
- 400
{- "status": "success",
- "group_id": "test"
}Delete an Image from the Logo Database
Delete an image from the logo database.
Note: This only deletes the image, not the logo, from the database. If you want to delete a logo, please use the delete_logo endpoint.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c", "group_id": "test" } }
Response samples
- 200
- 400
{- "status": "success",
- "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c",
- "group_id": "test"
}Delete a Logo from the Logo Database
Delete a logo from the logo database by specifying the logo_id and the group_id.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "logo_id": "adidas", "group_id": "test" } }
Response samples
- 200
- 400
{- "status": "success",
- "logo_id": "adidas",
- "group_id": "default"
}Download a Group from the Logo Database
Download an entire group dataset of images and logos within a group from the logo database as a .tar file.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "group_id": "test" } }
Response samples
- 200
- 400
<bytes (zip file)>
Get Group IDs from the Logo Database
Get the Group IDs of all the groups in the logo database.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "page": 1, "per_page": 1000 } }
Response samples
- 200
- 400
{- "status": "success",
- "group_id_list": [
- "default",
- "test",
- "mobius_core"
]
}Get Info of a Logo Group from the Logo Database
Get the Logo IDs and their image list IDs of all the logo within a specified group in the logo database.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "group_id": "default" } }
Response samples
- 200
- 400
{- "status": "success",
- "group_info": {
- "group_id": "default",
- "logo_count": 2,
- "negative_count": 512,
- "logos": [
- {
- "logo_id": "adidas",
- "image_id_list": [
- "b687ed5d-f09d-45e0-8e82-5089b957893c",
- "4c378112-38b6-4a19-a600-873f0d9ccbf1",
- "d6c21897-6f8a-40f6-8a2a-fab1cd762277",
- "3e59de55-35c7-49c4-b661-d64f376aa6dc",
- "8a5c057e-85bc-44fe-8885-83cf1e0180c8"
]
}, - {
- "logo_id": "nike",
- "image_id_list": [
- "fd02e442-e371-49a9-88b8-7511f8817710",
- "5a26d07e-bff1-449d-b142-f0231c6c27c1",
- "bb593098-8fb5-4219-88cd-063179a1d8f9",
- "69ede55c-1d42-45d0-a848-e9f2e121261f",
- "07f4c753-706a-4279-a08a-af03fd1de46a"
]
}
]
}
}Get Image IDs from the Logo Database
Get the Image IDs of all the images within a specified group in the logo database.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "page": 1, "per_page": 1000, "group_id": "default", "logo_id": "adidas" } }
Response samples
- 200
- 400
{- "status": "success",
- "image_id_list": [
- "b687ed5d-f09d-45e0-8e82-5089b957893c",
- "4c378112-38b6-4a19-a600-873f0d9ccbf1",
- "d6c21897-6f8a-40f6-8a2a-fab1cd762277",
- "3e59de55-35c7-49c4-b661-d64f376aa6dc",
- "8a5c057e-85bc-44fe-8885-83cf1e0180c8",
- "fd02e442-e371-49a9-88b8-7511f8817710",
- "5a26d07e-bff1-449d-b142-f0231c6c27c1",
- "bb593098-8fb5-4219-88cd-063179a1d8f9",
- "69ede55c-1d42-45d0-a848-e9f2e121261f",
- "07f4c753-706a-4279-a08a-af03fd1de46a"
]
}Get Logo IDs from the Logo Database
Get the Logo IDs of all the logos within a specified group in the logo database.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "page": 1, "per_page": 1000, "group_id": "default" } }
Response samples
- 200
- 400
{- "status": "success",
- "logo_id_list": [
- "adidas",
- "benz",
- "bmw"
]
}Get the Reference Image of a Logo
Get the reference logo image for a Logo ID from the Logo Database
Request Body schema: multipart/form-data
object |
Responses
Request samples
- cURL
- Python
curl "http://127.0.0.1:5000/system/database/logos/reference_image/get" \ -X POST \ -F params='{ "image_id": "b687ed5d-f09d-45e0-8e82-5089b957893c", "group_id": "test" }'
Response samples
- 200
- 400
<bytes>
Upload a Group to the Logo Database
Upload an entire group dataset of images and logos within a group to the logo database as a .tar file.
Request Body schema: multipart/form-data
object | |
| data required | string <binary> .tar file of the group. |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "group_id": "test" }, "data": "..." }
Response samples
- 200
- 400
{- "status": "success"
}Reset Default Logo Database
Reset default logo database to the SDK default one.
Request Body schema: multipart/form-data
| params | object |
Responses
Request samples
- cURL
- Python
curl "http://127.0.0.1:5000/system/database/logos/reset_default -X POST
Response samples
- 200
- 400
{- "status": "success"
}Add an Object to the Object Matching Database
Endpoint to add an image to the object matching database.
Request Body schema: multipart/form-data
object | |
| data required | string <binary> Image file |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c" }, "data": "..." }
Response samples
- 200
- 400
{- "status": "success",
- "image_id": "2ea8955a-939d-4a1c-93a6-34d68c06446c"
}Delete an Object from the Object Matching Database
Delete an object from the object matching database.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "object_id": "test" } }
Response samples
- 200
- 400
{- "status": "success",
- "object_id": "test"
}Download an Object from the Object Matching Database
Download an object from the object matching database as a .tar file.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "object_id": "test" } }
Response samples
- 200
- 400
<bytes (zip file)>
Get Object IDs from the Object Matching Database
Get the Object IDs of all the object registered in the object matching database.
Request Body schema: multipart/form-data
object |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "page": 1, "per_page": 1000 } }
Response samples
- 200
- 400
{- "status": "success",
- "object_id_list": [
- "Obj_A",
- "Obj_B"
]
}Upload an Object to the Object Matching Database
Upload an object to the object matching database from a .tar file.
Request Body schema: multipart/form-data
object | |
| data required | string <binary> .tar file of the object. This argument is required. |
Responses
Request samples
- Payload
- cURL
- Python
{ "params": { "object_id": "test" }, "data": "..." }
Response samples
- 200
- 400
{- "status": "success"
}This section is an inventory of all possible status messages and recommended actions.
Status messages contain two main fields: status and message.
The status can be either success, error, ongoing or in_queue to indicate the status of the processing.
Messages are shown in cases of errors or ongoing processing only.
SDK-level status messages
| Status message | Possible causes | Recommended solution |
|---|---|---|
| invalid_signature | Provided signature does not match the signature on token server. | Please check your token or contact us. |
| token_server_connection_error | System can't connect to the token verification server. | Please check the internet connection from inside the docker or contact us if the problem persists. |
| token_verification_error | Unexpected error happened in process of token verification | Please check your token and the connection to the internet from within the docker container. Contact us if the problem persists. |
| token_expired | Provided token is expired. | Please contact us. |
| token_error | Unexpected error happened during communicating with the token server | Please check the internet connection and the sdk logs for more info or send us the traceback and exception fields of the response. |
| token_not_provided | Token is not set as an environment var. | Please check your token to be provided as env var for the docker container. |
| token_info_not_found | processes are not fully initiated yet | Please check your token and the connection to the internet from within the docker container. Contact us if the problem persists. |
| token_not_found | Token is not registered in our token verification system. | Please check your token. |
| test_limit_reached | Token reached the maximum number of images that can be processed. Appears for test tokens with restriction. | Please contact us. |
| unexpected_error | Something unexpected happened. Catch-all error message. | Please send us the traceback and exception fields of the response. |
| endpoint_not_found | Requested endpoint does not exist. | Please check the requested endpoint. |
| parameters_decoding_error | The value in the field params is not a valid JSON document. |
Please check the value that is provided in the field params. |
| data_payload_required | No data was provided. | Please follow instructions from the documentation on how to fill in data. |
| multiple_data_sources | Multiple data sources are provided. | Specify exactly one of "file", "path", or "url". |
| parameters_validation_error | Provided parameters are not valid. | See description field for more information. |
| file_reading_error | Provided file has a wrong format or is corrupted. | Please check the file. |
| remote_connection_error | An attempt was made to fetch data from a remote source (most likely a data file specified with the url parameter) but the request failed. The remote server may be unavailable or the request may be invalid. |
Check that the url is correct and that the remote server is working correctly. |
| database_error | Error accessing database | Please make sure database service is up and running or contact us and attach logs (see Accessing logs). |
| unsupported_storage | Unsupported storage | Endpoint is currently not available for your storage type. Most likely, you're using old filesystem storage and that endpoint only supports new PostgreSQL storage. If you need access to that endpoint, your data has to be migrated. Contact us for more info. |
| image_reading_error | Various possible causes. SDK can't decode the image. This could be due to a corrupted image, or an unsupported image format. It could also be a problem with the library OpenCV/Pillow. | The on-premise SDK supports jpg and png image formats. Another possible solution is to verify that the image is not corrupted. |
| video_reading_error | Video codec/extension is not supported. | Our SDK uses ffmpeg as backbone, so please make sure that your video is supported by ffmpeg. |
| video_features_reading_error | Video Features file is corrupted. | Please check the video features file to contains the metadata and all the frames' features |
| video_defer_no_url | Defer option is on but no URL is provided in the request |
Check the request params to ensure that the url is set correctly. |
| video_id_not_found | Video features has not presented in the DB or has been deleted | Check the video_id in params or recalculate the video features first |
| video_in_progress | A active task for video is already in progress | Check the task status and wait for the task to be finished |
| file_saving_error | The SDK can't save a file or extract features. Could be caused by a problem with the file system or data directory in docker. | Please verify that write access is given and that there is enough free space. |
| task_id_not_found | Provided task ID is not registered in the system. Could be caused by passing the wrong task ID. | Please verify the correctness of the task ID. |
| timeout_error | SDK is busy with so many requests. | Please retry later. |
| inference_timeout_error | SDK is busy with so many requests. | Please retry later. |
| out_of_memory | GPU memory is not enough for loading all the models | Please contact us |
| inference_error | SDK internal error. | Please contact us. |
Status messages for standard concept module
| Status message | Possible causes | Recommended solution |
|---|---|---|
| config_not_found | Requested name of the configuration file is not registered in the SDK. | Please verify that the name is correct or upload a configuration file. |
Status messages for custom concept module
| Status message | Possible causes | Recommended solution |
|---|---|---|
| training | Training is going on. This is the message for the status 'ongoing'. | Please wait for training to complete. |
| training_initialization_error | Training failed to start. | Please contact us. |
| training_error | Training process has failed. | Please contact us. |
| task_id_not_found | Provided task ID is not registered in the system. Could be caused by passing the wrong task ID. | Please verify the correctness of the task ID. |
| image_id_exists | Provided image ID is already in use. This can happen if the same image is passed to the add function multiple times. | Please check the image IDs for uniqueness and remove duplicates. |
| image_id_assigned | Provided image ID is used by one of the custom concepts. | Remove custom concept or unassign image from the custom concept. |
| image_id_not_found | Provided image ID is not found. | Please check the image ID. |
| not_enough_images_assigned | The SDK has not been provided with any positive samples. It is required for training to have positive samples. | Please add positive samples. |
| custom_concept_exists | Custom concept with that ID already registered in the system. | Delete custom concept or use a different custom concept ID. |
| features_loading_error | The system can't load features from the disk for training. Could be caused by having no read rights or file system issues. | Verify the location of features and that read access is given. |
| custom_concept_loading_error | Custom concept cannot be loaded. | Probably the custom concept is corrupted. Delete it and retrain or upload the custom concept again. |
| custom_concept_id_not_found | Requested custom concept ID does not exist. | Please make sure the correct custom concept ID is passed. |
Status messages for custom style module
| Status message | Possible causes | Recommended solution |
|---|---|---|
| training | Training is going on. This is the message for the status 'ongoing'. | Please wait for training to complete. |
| training_initialization_error | Training failed to start. | Please contact us. |
| training_error | Training process has failed. | Please contact us. |
| task_id_not_found | Provided task ID is not registered in the system. Could be caused by passing the wrong task ID. | Please verify the correctness of the task ID. |
| image_id_exists | Provided image ID is already in use. Can happen if the same image is passed to the add function multiple times. | Please check the image IDs for uniqueness and remove duplicates. |
| image_id_assigned | Provided image ID is used by one of the custom style. | Remove custom style or unassign image from the custom style. |
| image_id_not_found | Provided image ID is not found. | Please check the image ID. |
| not_enough_images_assigned | The SDK has not been provided with any positive samples. It is required for training to have positive samples. | Please add positive samples. |
| custom_style_exists | Custom style with that ID already registered in the system. | Delete custom style or use different custom style ID. |
| features_loading_error | The system can't load features or load features from disk for training. Could be caused by having no read rights or file system issues. | Verify location of features and that read access is given. |
| custom_style_loading_error | Custom style can not be loaded. | Probably custom style is corrupted. Delete it and retrain or upload the custom style again. |
| custom_style_id_not_found | Requested custom style ID does not exist. | Please make sure the correct custom style ID is passed. |
Status messages for image similarity module
| Status message | Possible causes | Recommended solution |
|---|---|---|
| task_id_not_found | Provided task ID is not registered in the system. Could be caused by passing the wrong task ID. | Please verify the correctness of the task ID. |
| image_id_exists | Provided image ID is already in use. Can happen if the same image is passed to the add function multiple times. | Please check the image IDs for uniqueness and remove duplicates. |
| index_loading_error | Similarity search module can't load the search approximator. Can happen when the user has not trained it. Also when no images have been added to the index. It can be a problem with the file system. | Please use proper set-up for adding images as explained in the documentation and check file system access. |
| not_enough_images_added | This feature needs at least 1000 samples to train similarity search in the initial training round. | Please add more images prior to training. |
| training | Training is going on. This is the message for the status ongoing. |
Please wait for training to complete. |
| training_initialization_error | Training failed to start. | Please contact us. |
| training_error | Training process has failed. | Please contact us. |
| updating | Updating is going on. This is the message for the status ongoing. |
Please wait for update to complete. |
| training_in_progress | The index training or updating is in progress. | Please wait for training or update to complete. |
Status messages for face recognition module
| Status message | Possible causes | Recommended solution |
|---|---|---|
| image_id_exists | Provided image ID is already in use. Can happen if the same image is passed to the add function multiple times. | Please check the image IDs for uniqueness and remove duplicates. |
| image_id_not_found | Provided image ID is not found. | Please check the image ID. |
| index_loading_error | Face recognition module can't load face search index. | |
| no_face_detected | No faces are detected on the provided image. | Provide another image. |
| multiple_faces_detected | More than one face is detected. | Provide another image that contains exactly one face. |
| face_too_small | Detected face is too small for the provided image. | Provide another image or same image in higher resolution. |
| person_id_not_found | Provided person ID is not found. | Please check the person ID. |
| group_id_not_found | Provided group ID is not found. | Please check the group ID. |
| not_implemented_exception | The endpoint is not implemented for the SDKs storage type. | Get in touch to get an |
| upgrade to the more effective storage engine. |
Status messages for free-text search module
| Status message | Possible causes | Recommended solution |
|---|---|---|
| query_too_long | Provided query is too long. | Please use shorter query. |
Status messages for unlabeled imagery
| Status message | Possible causes | Recommended solution |
|---|---|---|
| unlabeled_set_not_found | Requested unlabeled set does not exist. | Request different unlabeled set or add unlabeled set to the unlabeled imagery dataset. |
| unlabeled_set_exists | Requested name for new unlabeled set is in use. | Use different name for unlabeled set or delete existed one first. |
| unlabeled_set_is_protected | Unlabeled set provided by SDK is protected and can not be deleted. | Please contact us. |
Status messages for custom detection module
| Status message | Possible causes | Recommended solution |
|---|---|---|
| unlabeled_set_not_found | Requested unlabeled set does not exist. | Request different unlabeled set or add unlabeled set to the unlabeled imagery datasets. |
| image_id_exists | Provided image ID is already in use. This can happen if the same image is passed to the add function multiple times. | Please check the image IDs for uniqueness and remove duplicates. |
| image_id_assigned | Provided image ID is used by one of the custom detectors. | Remove custom detector or unassign image from the custom detector. |
| image_id_not_found | Provided image ID is not found. | Please check the image ID. |
| ill_formed_bounding_box | Provided bounding box is ill-formed. | Provide the corrected box or adjust annotation_type. |
| base_model_not_found | Requested base model does not exist. | Request different base model or add base model to the custom detection database |
| base_model_exists | Requested name for base model is in use. | Use different name for base model or delete existed one first. |
| base_model_is_protected | Base model provided by SDK is protected and can not be deleted. | Please contact us. |
| custom_detector_id_not_found | Requested custom detector ID does not exist. | Please make sure the correct custom detector ID is passed. |
| custom_detector_exists | Requested name for custom detector is in use. | Use different name for custom detector or delete or rename existed one first. |
| custom_detector_is_protected | Custom detector provided by SDK is protected and can not be deleted. | Please contact us. |
| no_custom_detector_id_selected | No custom detectors is selected for prediction. | Add some custom detector id in request or set default custom detector list for prediction |
| custom_detector_loading_error | Custom detection failed to start. | Please contact us. |
| file_reading_error | Provided file has a wrong format or is corrupted. | Please check the file. |
| not_enough_images_assigned | The SDK has not been provided with any training image samples for each custom detector. It is required for training to have at least 1 image is assigned for each custom detectors. | Please assign training images with annotations to each custom detectors. |
| not_enough_objects_assigned | For training a Custom detector you should provide at least 1 bounding box for each custom detector | Please add some bounding box for defined custom detectors. |
| invalid_input_size | The input size provided for training a custom detector is not valid. | Please read the description of input_size in creating base model endpoint. |
| out_of_memory | GPU memory is not enough for training or loading the models | Please use smaller input_size or contact us |
The on-premise SDK comes with a default configuration file, named default. The user can fully customize these settings and create their own custom configuration files.
The name of the configuration file is passed during prediction time in the prediction call in order to specify which setting to use (see /tags/standard_concepts/config_name in the parameters of the /image/predict endpoint).
The naming of the configuration files enables the usage of multiple configuration files in the same SDK.
There are three endpoints to manage configuration files:
Configuration files allow users to customize the following settings:
Concept Categories
By default, prediction results are grouped by 13 categories that are pre-defined by Mobius Labs, as follows:

The configuration file for standard concepts allows users to assign a concept to a different category.
The formatting of this assignment looks as follows:
acorn:
- nature
acoustic guitar:
- things
acoustic music:
- conceptual
Mapping List
Mapping allows the user to replace a pre-trained concept in the Mobius SDK with another concept that is more suitable to the users’ use case. There are two main usages of the mapping:
- Map a concept
Ato another existing conceptB: only the concept nameBwill be returned to the user. The confidence score will be the maximum score of confidence scores ofAandB. - Rename a concept: Assign a concept
Aa new labelC. When the conceptAis predicted, it will show the labelCinstead of the original concept nameA.
This is an example of the formatting in the configuration file:
bumblebee: insect
burger: hamburger
buttercream: icing
Stop List
The stop list allows users to remove concepts from the predictions.
This is an example of the formatting in the configuration file:
- gangster
- graphic designer
- hippie
Antonym List
Antonyms specify concepts that are not supposed to appear in the same image together. For each pair of concepts listed as antonyms, only the one with higher confidence score will be returned, even if both concepts have been predicted.
This is an example of the formatting in the configuration file:
- - daughter
- no people
- - dawn
- dusk
- - day
- night
General Support
You can reach our support most conveniently by sending an email to support.onpremise@mobius.com.
If you’d like to get other features, or versions for other platforms (Android, iOS), feel free to contact our friendly colleagues at the sales team. You can reach them at sales@mobius.com.
Data Protection
The Mobius Labs privacy policy can be found on our website: Link to website
You can find other general information about the company in the website imprint: Link to website
If you have any concerns regarding data privacy please contact our data privacy officer: datenschutz@mobius.com
Model
We use the term model to refer to computer vision components that are using neural networks.
Module
module refers to the features that can be packaged into the SDK. We only deliver modules in the SDK that are included in the license contract.
Token
We use a short unique sequence for each client and SDK that we call token. It will be provided by your delivery manager when you get the SDK. You need to pass the token when running the SDK.